Lá no nosso canal do Youtube nós conversamos um pouco sobre alguns conceitos básicos de causalidade. Falamos sobre a importância de ter um grafo descrevendo a relação entre as nossas variáveis para que a gente não seja enganado pelas correlações espúrias, sobre viéses de seleção e, no final, mostramos a aplicação de um método para construir um grafo de relacionamento entre as nossas variáveis usando o algoritmo PC. Neste post, vamos te mostrar como implementar esse algoritmo nas suas bases de dados.
Entretanto, antes de implementar o algoritmo, vamos analisar como funciona esse algoritmo.
Funcionamento geral do algoritmo PC
A principal ideia por trás do algoritmo PC é que, dadas três variáveis \(X\), \(Y\), \(Z\), o único jeito de verificarmos \(X \not\perp Y | Z\) (isso é, não X é independente de Y quando condicionamos no valor da variável Z) é se a relação causal entre elas for \(X \rightarrow Z \leftarrow Y\) (\(Z\) é um colisor). Se \(X \perp Y \ | \ Z\) fosse verdade, qualquer uma das setas (ou todas) poderiam estar ao contrário do que estão em \(X \rightarrow Z \leftarrow Y\).
Sendo assim, o algoritmo PC consegue decidir onde fica a ponta de algumas das setinhas usando esse critério e repetir esses testes sucessivamente. Em linhas gerais, o algoritmo faz o seguinte:
- Comece com um grafo em que todas as variáveis estão conectadas, mas sem a ponta das setas.
- Para todo par de variáveis \(X\) e \(Y\), verifique se \(X \perp Y\). Se a resposta for “Sim”, remova essa conexão.
- Para todo par de variáveis \(X\) e \(Y\) e para todo conjunto de variáveis \(S = \{Z_1, Z_2, ...\}\) que não contem \(X\) e \(Y\), verifique se \(X \perp Y \ | \ S\). Se a resposta for “Sim”, remova essa conexão.
- Para todas as triplas de variáveis que sobraram \(X - Z - Y\), verifique se \(X \not \perp Y \ | \ Z\). Se a resposta for “Sim”, oriente essas setinhas na direção de \(Z\).
- Caso haja alguma setinha que está sem orientação, utilize o resultado dos testes que obteve no passo 3. para eventualmente orientar algumas outras setar por exclusão.
O algortimo PC no pacote bnlearn
library(bnlearn)
library(tidyverse)Similar ao que fizemos na live, aqui vamos procurar um grafo de relacionamentos entre as variáveis da base Auto, disponível no pacote ISLR. Vamos excluir algumas variáveis dessa base e aplicar algumas transformações:
dados_para_ajuste <- ISLR::Auto %>%
dplyr::select(-name, -origin)
# Vamos excluir algumas variáveis estritamente qualitativasPara buscar as relações entre as variáveis da tabela dados_para_ajuste, basta utilizarmos a função bnlearn::pc.stable, cujo resultado pode ser plotado usando a função plot.
dados_para_ajuste %>%
bnlearn::pc.stable(alpha = .01) %>%
plot()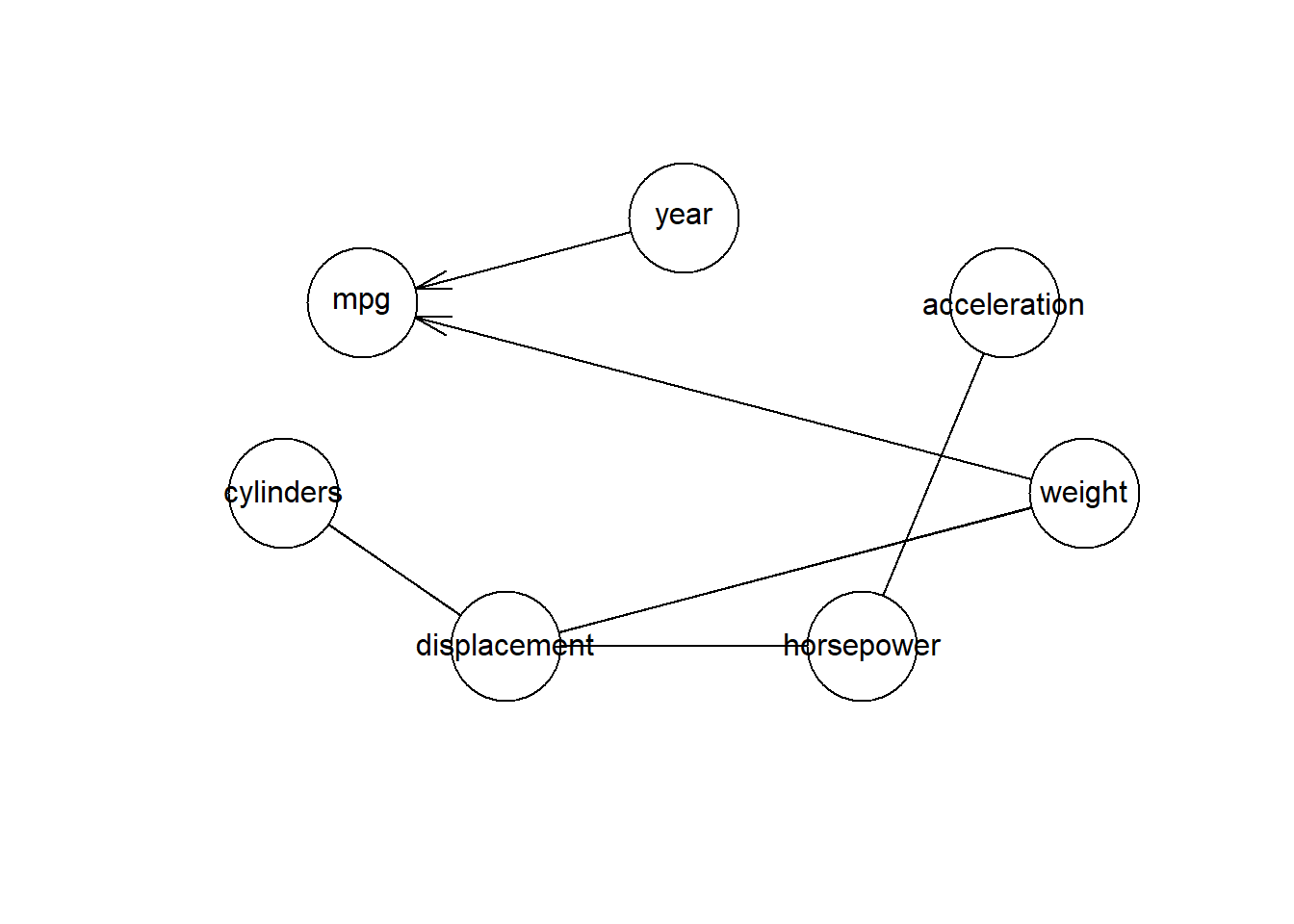
Bacana, né? O melhor é que é simples. Esse pacote, inclusive, permite que a gente misture variáveis contínuas e categórias, basta trocar a opção de teste de independência no parâmetro test.
Gostou? Quer saber mais?
Se você quiser aprender um pouco mais sobre esse assunto, temos alguns cursos que tocam os temas deste post. Dê uma olhada nos nossos cursos de Regressão Linear ou Machine Learning e aproveite!
Se você quiser aprender um pouco mais sobre manipulação de dados com R, dê uma olhada no nosso curso R para Ciência de Dados I e aproveite!
Caso você tenha dúvidas entre em contato com a gente pelos comentários aqui embaixo, pelo nosso Discourse ou pelo e-mail contato@curso-r.com.


