Alô alôww Comunidade
Lançamos uma competição Kaggle e agora é a hora de você mostrar que é Jedi em DATA SCIENCE! =D
Link: https://www.kaggle.com/c/guess-the-correlation/
A gente fez isso por esporte, favor não tentar achar utilidade nessa aplicação =P.
O Jogo
O site Guess The Correlation coloca o ser humano frente a frente com um gráfico de dispersão em que é em seguida desafiado a adivinhar a respectiva a correlação linear.
No nosso desafio Kaggle, desafio similar foi construído. Por exemplo: quanto você chutaria que é a correlação entre os dados da figura abaixo?
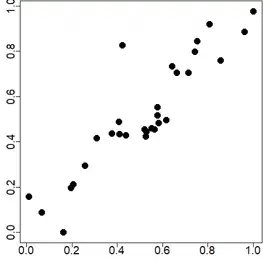
Foram geradas 200 mil imagens em png como a figura acima e cada uma delas tem a sua correleção anotada para treinarmos um modelinho.
Objetivo
O objetivo é simples e direto: construir um robô que calcula a correlação (linear) apenas vendo o gráfico de dispersão.
Em machine lârnês, queremos
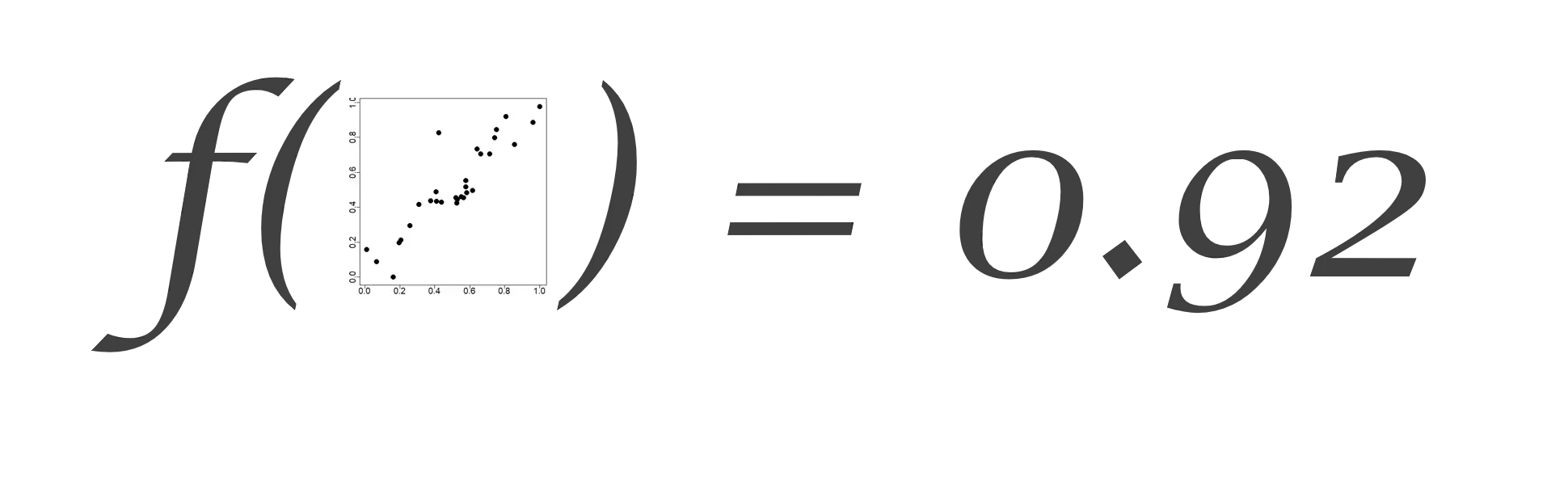
em que essa f seja digna de ser f de F@!#.
Chute inicial
O Julião já andou trabalhando nesse problema e deu um chute inicial nos códigos pra vocês se inspirarem. Aliás, “inicial” numas, porque ele já saiu fazendo um CNN com a ajuda do pacote decryptr:
library(keras)
library(tidyverse)
library(decryptr)
path <- "."
arqs <- dir(paste0(path, "/train_imgs"), full.names = TRUE)
resp <- readr::read_csv(paste0(path, "/train_responses.csv"))
i_train <- sample(1:nrow(resp), 10000)
arqs_train <- arqs[i_train]
arqs_test <- arqs[-i_train]
gen <- function(batch_size = 100, arqs = arqs_train) {
f <- function() {
a <- sort(sample(arqs, batch_size))
imgs <- decryptr::read_captcha(a)
captchas_t <- purrr::transpose(imgs)
xs <- captchas_t$x
xs <- abind::abind(xs, along = 0.1)
a_clean <- a %>%
basename() %>%
tools::file_path_sans_ext() %>%
tolower()
corr <- resp %>%
filter(id %in% a_clean) %>%
arrange(id) %>%
pull(corr)
data <- list(xs, corr)
data
}
f
}
# Create model
model <- keras_model_sequential()
model %>%
layer_conv_2d(
input_shape = c(150, 150, 1),
filters = 16, kernel_size = c(3, 3),
padding = "same",
activation = "relu") %>%
layer_max_pooling_2d() %>%
layer_conv_2d(
filters = 32, kernel_size = c(3, 3),
padding = "same",
activation = "relu") %>%
layer_max_pooling_2d() %>%
layer_conv_2d(
filters = 64, kernel_size = c(3, 3),
padding = "same",
activation = "relu") %>%
layer_max_pooling_2d() %>%
layer_flatten() %>%
layer_dense(units = 300) %>%
layer_dropout(.1) %>%
layer_dense(units = 1, activation = "tanh")
# Compile and fit model
model %>%
compile(
optimizer = "sgd",
loss = "mean_squared_error",
metrics = "mean_squared_error")
model %>%
fit_generator(
gen(100, arqs_train),
steps_per_epoch = 100,
validation_data = gen(100, arqs_test),
validation_steps = 10
)E aí? Será que dá pra acertar 100%? Ou será impossível?
Boa R’ada!


