Na jornada da ciência de dados, muitas vezes precisamos rodar um mesmo algoritmo em vários objetos distintos. Quando o algoritmo é pesado ou a lista de objetos é longa, é importante saber em que passo estamos e quanto vai demorar para terminar.
Uma forma de resolver esse problema é usando o pacote progress. O objeto progress_bar desse pacote é do tipo R6 e tem um método new() para criar objetos do tipo “barra”. Uma barra criada também é do tipo R6 e possui o método tick() para imprimir uma barra de progresso no console.
No exemplo abaixo, nosso interesse é aplicar a função funcao_demorada nos números 1:5 (um de cada vez, sem usar vetorização) e guardá-los numa lista.
funcao_demorada <- function(x) {
Sys.sleep(0.5)
x ^ 2
}
nums <- 1:5Podemos fazer isso usando o pacote progress:
barra <- progress::progress_bar$new(total = length(nums)) # cria a barra
resultados <- list()
for (x in nums) {
barra$tick() # dá um passo
resultados[[x]] <- funcao_demorada(x)
}TRUE [===========================>-------------------------------------------] 40%
TRUE [==========================================>----------------------------] 60%
TRUE [========================================================>--------------] 80%
TRUE [=======================================================================] 100%Como resultados, temos:
resultados
## [[1]]
## [1] 1
##
## [[2]]
## [1] 4
##
## [[3]]
## [1] 9
##
## [[4]]
## [1] 16
##
## [[5]]
## [1] 25No entanto, sabemos que os laços for e while do R são problemáticos. A melhor e mais estilosa forma de fazer esse tipo de operação no R é usando funcionais.
Funcionais são funções de funções. Usamos esses caras sempre que queremos aplicar uma função a diversos objetos. Eles são alternativas mais concisas, elegantes e muitas vezes mais eficientes do que os conhecidos for e while.
Exemplos de funcionais são os objetos da família **ply (lapply, apply, sapply etc.) Os funcionais do R básico foram generalizados no pacote plyr, que apresenta uma sintaxe organizada e intuitiva.
Uma vantagem do plyr é a possibilidade de adicionar barras de progresso como um parâmetro dos funcionais.
resultados <- plyr::llply(nums, funcao_demorada, .progress = 'text')
##
|
| | 0%
|
|============== | 20%
|
|============================ | 40%
|
|========================================== | 60%
|
|======================================================== | 80%
|
|======================================================================| 100%Os resultados são idênticos e foram omitidos. Bem mais simples, não?
Usando purr::map no lugar de plyr::llply
Recentemente, boa parte das funções do plyr foram substituídas por alternativas nos pacotes dplyr (operações envolvendo data.frames) e purrr (operações envolvendo vetores e listas). Esses pacotes apresentam uma sintaxe mais próxima da filosofia tidy e portanto faz sentido estudá-los!
Infelizmente, as funções do purrr ainda1 não têm um parâmetro para barras de progresso. Enquanto isso, podemos utilizar o progress::progress_bar mesmo.
barra <- progress::progress_bar$new(total = length(nums))
resultados <- purrr::map(nums, ~{
barra$tick()
funcao_demorada(.x)
})TRUE [===========================>-------------------------------------------] 40%
TRUE [==========================================>----------------------------] 60%
TRUE [========================================================>--------------] 80%
TRUE [=======================================================================] 100%O código fica parecido com solução usando for(), mas pelo menos estamos usando os pacotes mais recentes ;)
Eficiência
As soluções que mostrei acima apresentam diferenças importantes de eficiência. Abaixo, encapsulei os códigos em funções e mudei levemente a operação que queremos fazer:
nums <- 1:100
funcao_rapida <- function(x) {
x ^ 2
}for(), com e sem progresso:
for_com <- function(nums) {
barra <- progress::progress_bar$new(total = length(nums))
resultados <- list()
for(x in nums) {
barra$tick()
resultados[[x]] <- funcao_rapida(x)
}
resultados
}
for_sem <- function(nums) {
resultados <- list()
for(x in nums) resultados[[x]] <- funcao_rapida(x)
resultados
}plyr::llply(), com e sem progresso:
plyr_com <- function(nums) {
plyr::llply(nums, funcao_rapida, .progress = 'text')
}
plyr_sem <- function(nums) {
plyr::llply(nums, funcao_rapida)
}purrr::map(), com e sem progresso:
purrr_com <- function(nums) {
barra <- progress::progress_bar$new(total = length(nums))
purrr::map(nums, ~{
barra$tick()
funcao_rapida(.x)
})
}
purrr_sem <- function(nums) {
purrr::map(nums, funcao_rapida)
}Para testar a eficiência dos algoritmos, utilizamos a função microbenchmark::microbenchmark(). Essa função calcula o tempo de execução do algoritmo cem vezes e obtém algumas estatísticas básicas dos tempos obtidos.
benchmark <- microbenchmark::microbenchmark(
for_com(nums), for_sem(nums),
plyr_com(nums), plyr_sem(nums),
purrr_com(nums), purrr_sem(nums)
)Os resultados da Tabela 1 são surpreendentes. Primeiro, as funções que não usam barras de progresso são muito mais rápidas, chegando a quase 10 vezes em alguns casos. A função do plyr é mais lenta que o for() quando usamos barras de progresso, mas é mais rápida quando não usamos. O purrr é o mais rápido nos dois casos.
| expr | min | mean | median | max |
|---|---|---|---|---|
| for_com(nums) | 8.666 | 10.367 | 9.952 | 17.155 |
| for_sem(nums) | 0.161 | 0.219 | 0.196 | 2.211 |
| plyr_com(nums) | 9.193 | 10.754 | 10.511 | 18.386 |
| plyr_sem(nums) | 0.116 | 0.155 | 0.156 | 0.271 |
| purrr_com(nums) | 8.776 | 10.376 | 9.982 | 14.424 |
| purrr_sem(nums) | 0.092 | 0.131 | 0.124 | 0.538 |
Mas não leve esses resultados tão a sério. Na prática, a parte mais demorada fica na função aplicada e não no funcional utilizado, implicando que essas diferenças sejam ignoráveis. Só recomendo mesmo abandonar o for() para operações desse tipo, pois o tempo de execução não cresce linearmente com o tamanho dos objetos, como é possível ver na Figura 1.
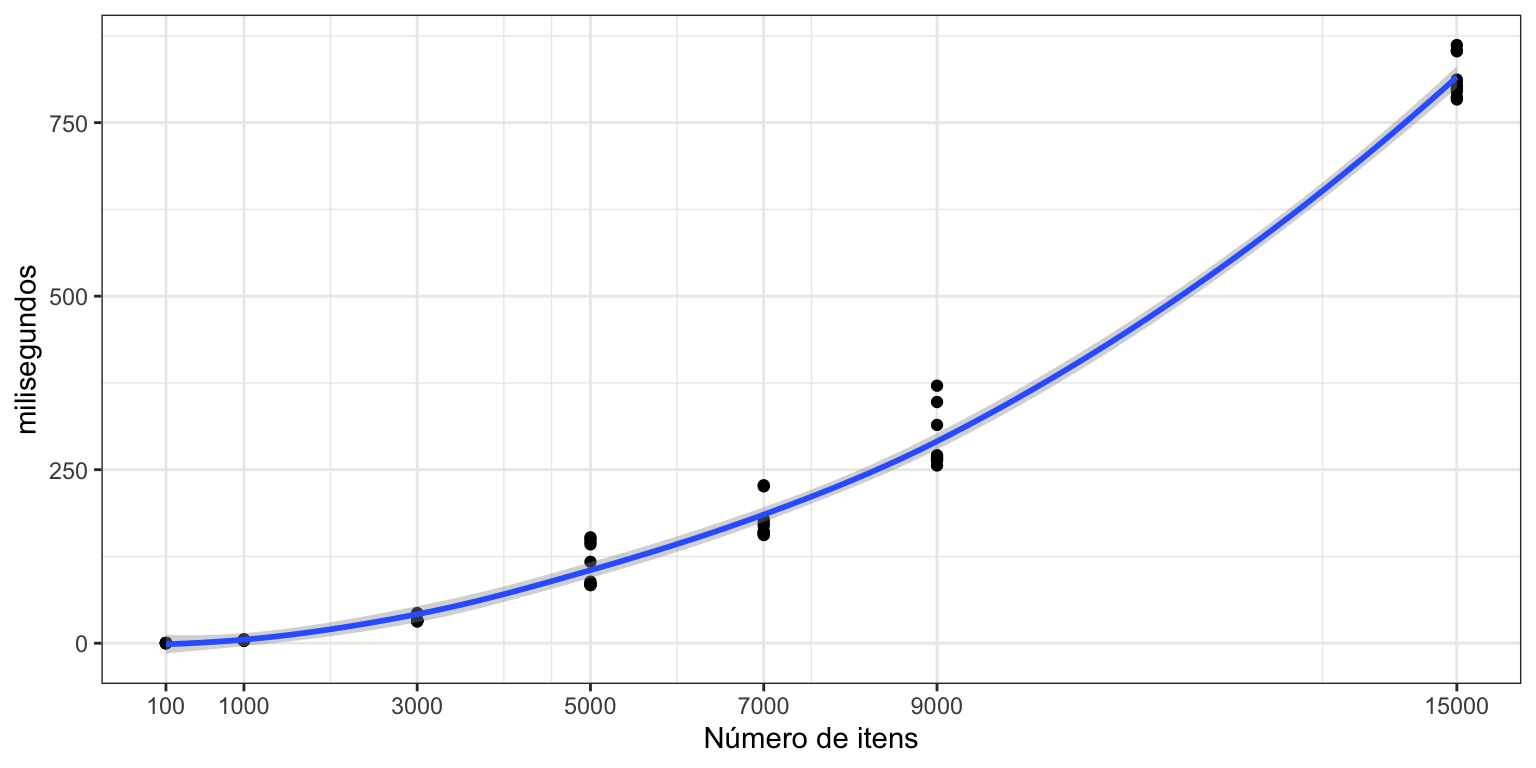
Figura 1: Tempo do for em função do número de inputs
Resumo
- Use o objeto
progress::progress_barsempre que quiser fazer barras de progresso. - Use o método
$new(total = n)para criar uma barra. - Use o método
$tick()dentro do loop para mostrar que andou um passo do algoritmo. - Tome cuidado com a eficiência do algoritmo quando usa barras de progresso.
Outros links
- Veja
?dplyr::progress_estimated. - Pacote
progress. - Programação funcional.
É provável que o
purrrganhe essa funcionalidade num futuro próximo. Veja essa discussão.↩︎


