O tidyr é um pacote muito útil para arrumar os dados, ou seja, deixá-los tidy. Dizemos que os dados estão arrumados quando
- cada coluna é uma variável;
- cada linha é uma observação;
- cada célula representa um único valor.
O lançamento da versão 1.0.0 (em 09/11/19) apresentou uma grande mudança do pacote: a substituição das funções gather() e spread() pelas novas funções pivot_longer() e pivot_wider().
Neste post, vamos apresentar o que mudou nessas novas funções e mostrar como aplicar as operações de pivotagem nesse novo framework.
Os dados
Para ilustrar a utilização das funções, vamos criar uma tabelinha bem simples, que nos permita visualizar a mudança entre os formatos long e wide.
Suponhamos que os dados a seguir representem as vendas de duas lojas nos meses de janeiro a junho de um determinado ano. É muito comum recebermos uma tabela no formado wide.
dados <- tibble::tribble(
~loja, ~jan, ~fev, ~mar, ~abr, ~mai, ~jun,
1, 20, 30, 23, 10, 40, 55,
2, 30, 43, 29, 15, 40, 60
)
dados
## # A tibble: 2 x 7
## loja jan fev mar abr mai jun
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 20 30 23 10 40 55
## 2 2 30 43 29 15 40 60Repare que, embora nessa tabela existam 3 variáveis, apenas 2 estão explícitas: a loja e o mês. As vendas estão apenas no corpo da tabela e, sem contexo, não saberíamos o que esses valores significam.
Além disso, essa tabela não está no formato tidy, pois cada coluna não represta uma variável: a variável mês está espalhada nas colunas e a variável vendas não é uma coluna.
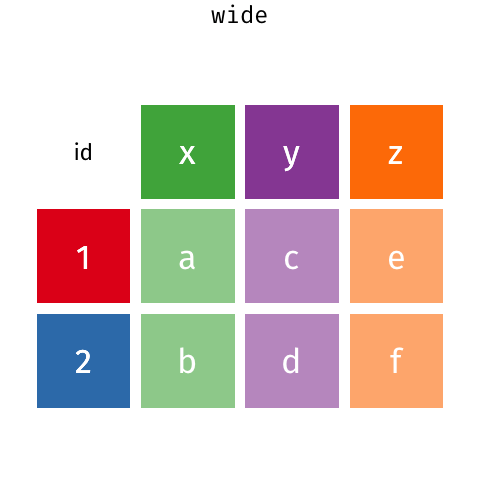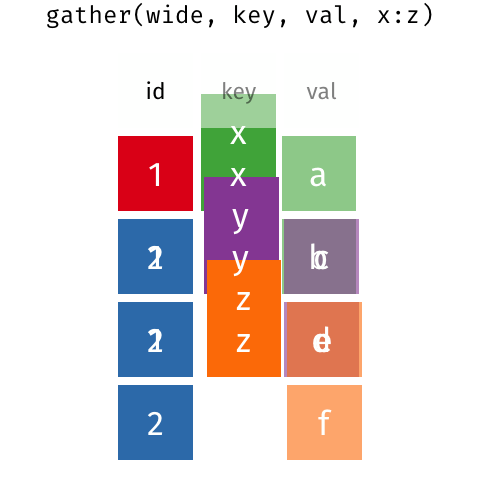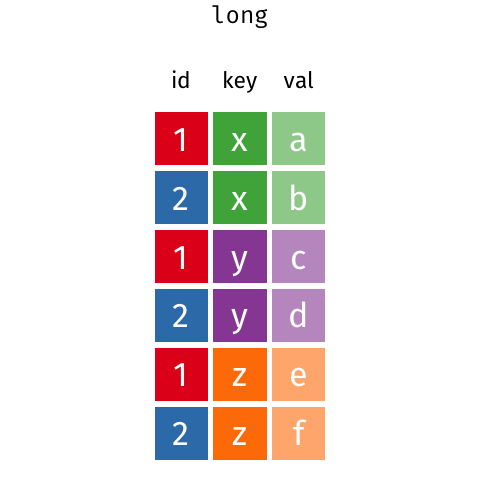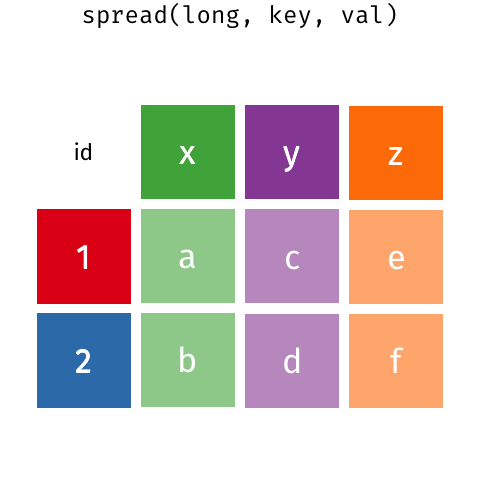
A seguir, vamos ver como utilizar as antigas funções gather() e spread() para deixar essa tabela tidy (ou para, uma vez tidy, voltar ao formato original).
As antigas funções gather() e spread()
Para deixar os dados arrumados com as três variáveis (mês vendas e loja) como colunas, usamos a função gather(). Essa função vai transformar as colunas de janeiro a junho em valores de uma única coluna e vai criar uma nova coluna com os dados de vendas.
library(tidyr)
dados_gather <- dados %>%
gather(jan:jun, key = "mes", value = "vendas")
dados_gather
## # A tibble: 12 x 3
## loja mes vendas
## <dbl> <chr> <dbl>
## 1 1 jan 20
## 2 2 jan 30
## 3 1 fev 30
## 4 2 fev 43
## 5 1 mar 23
## 6 2 mar 29
## 7 1 abr 10
## 8 2 abr 15
## 9 1 mai 40
## 10 2 mai 40
## 11 1 jun 55
## 12 2 jun 60Aqui estamos selecionando as colunas de janeiro a junho e aplicando gather(). O argumento key recebe o nome da variável com os nomes das colunas (no nosso exemplo, meses) e value recebe o nome da variável com as observações das colunas, vendas.
Ok, conseguimos deixar nossos dados no formato tidy. Será que é possivel retorná-los ao formato original?
Para isso, precisamos de uma função que faça o inverso de gather(), “espalhando” as observações da variável mês em várias colunas e transformando vendas em observações dessas colunas. No pacote {tidyr} essa função se chama spread().
dados_spread <- dados_gather %>%
spread(key = mes, value = vendas)
dados_spread
## # A tibble: 2 x 7
## loja abr fev jan jun mai mar
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 10 30 20 55 40 23
## 2 2 15 43 30 60 40 29Observe que o argumento key indica o nome da variável que será espalhada em várias colunas e o argumento value indica o nome da variável que vai ser transformada em observações.
No {tidyr} 1.0.0, essas funções foram aprimoradas, recebendo nomes e argumentos mais intuitivos e fáceis de lembrar, além de apresentarem mais possibilidade de uso a fim de auxiliar na tarefa de estruturar os dados.
As novas funções pivot_longer() e pivot_wider()
O pivot_longer(), em casos mais simples, equivale a função gather(). Esse nome foi dado pois, ao rodar a função, o banco de dados se torna mais longo (longer) em relação aos dados originais.
dados_longer <- dados %>%
pivot_longer(
cols = jan:jun,
names_to = "mes",
values_to = "vendas"
)
dados_longer
## # A tibble: 12 x 3
## loja mes vendas
## <dbl> <chr> <dbl>
## 1 1 jan 20
## 2 1 fev 30
## 3 1 mar 23
## 4 1 abr 10
## 5 1 mai 40
## 6 1 jun 55
## 7 2 jan 30
## 8 2 fev 43
## 9 2 mar 29
## 10 2 abr 15
## 11 2 mai 40
## 12 2 jun 60A função spread() foi substituida por pivot_wider(). Ela vai transformar os dados em um formato mais largo. Veja que as duas funções funcionam de forma equivalente.
dados_wider <- dados_longer %>%
pivot_wider(names_from = mes, values_from = vendas)
dados_wider
## # A tibble: 2 x 7
## loja jan fev mar abr mai jun
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 20 30 23 10 40 55
## 2 2 30 43 29 15 40 60Essas novas funções de pivotagem trazem várias outras funcionalidades para remodelar as bases de dados. Vamos falar delas em novos posts. Em quanto isso, se você quiser conferir, basta acessar o vignette do tidyr (inglês).


