O Porta dos Fundos (PDF) é um dos meus canais preferidos do youtube. Com mais de 5 bilhões de visualizações e diversos vídeos que já fazem parte da nossa cultura (drébito?), o PDF é um canal que divide opiniões. Muitos consideram que é um dos maiores grupos de humor do século. Outros acreditam que eles começaram muito bem, mas que agora já perderam a graça.
Outros dizem que é um grupo de esquerdistas planejando a revolução comunista:
Polêmicas a parte, fato é que, com mais de sete anos de história e mais de mil vídeos, o PDF é um prato cheio para quem quer fazer análise de dados com o R. E é isso que faremos agora!
Nesse post, pretendo revisitar as análises realizadas pelo William e pelo Fernando, dessa vez abrindo os resultados por artista. A pergunta que eu gostaria de responder é: quem segura a barra do PDF? Ou seja, quais artistas estão associados a vídeos com mais visualizações, e quem acumulou mais vídeos ao longo dos anos?
Minha hipótese era de que o Rafael Portugal é a pessoa que segura o PDF nas costas. Vamos verificar?
Se quiser reproduzir as análises do artigo, carregue esses pacotes aqui:
library(tidyverse)
library(lubridate)
library(httr)
library(xml2)
library(jsonlite)
library(janitor)
library(fs)Obtendo e arrumando dados
Acessando o site do PDF, descobri que seria fácil obter uma lista de todos os vídeos do canal. O site é alimentado por uma API construída em Firebase, uma solução do Google. Para acessar essa API, bastou entrar no site e encontrar a chave de acesso nos headers. A chave se parece com isso:
Public XN@dm5L$i8trI+*qy}p&|lcF...Montei uma função pegar_pag() para fazer o loop das páginas da API. O final é o código abaixo:
pegar_pag <- function(u, key) {
h <- add_headers(Authorization = key)
r <- GET(u, h)
content(r, "parsed")
}
# pegando os json de todas as paginas
json_list <- list()
u <- "https://porta.pixelwolf.co/api/v1/videos/?sort=-publish_date"
while(!is.null(u)) {
message(u)
json <- list(pegar_pag(u))
json_list <- append(json_list, json)
u <- json[[1]][["next"]]
}Depois, montei um script para arrumar e guardar esses dados. Para quem não sabe, o pacote {magrittr} permite a criação de funções anônimas utilizando o atalho funcao <- . %>% .... Isso é equivalente a fazer funcao <- function(.) {...}
# arrumando os json
arrumar_um_item <- . %>%
discard(is.null) %>%
magrittr::extract(!names(.) %in% c("making_of", "serie")) %>%
as_tibble() %>%
distinct(id, .keep_all = TRUE)
arrumar_um_json <- . %>%
pluck("results") %>%
map_dfr(arrumar_um_item)
da_site_pdf <- json_list %>%
map_dfr(arrumar_um_json) %>%
distinct(id, .keep_all = TRUE)Essa base de dados contém algumas informações sobre os vídeos, como nome, link do youtube e descrição. No entanto, ela não possui duas informações que queremos muito: o número de likes e o elenco.
Obtendo informações do elenco
Para conseguir essas informações, acessamos as páginas individuais de cada link listado no passo anterior.
get_elenco <- function(slug) {
message(slug)
u_pag <- paste0("https://www.portadosfundos.com.br/video/", slug)
get <- insistently(GET, rate_delay(0.1, 100))
r <- get(u_pag, timeout(1))
r %>%
read_html() %>%
xml_find_all("//a[@class='cast-item']") %>%
xml_attr("href")
}
da_elenco_pdf <- da_site_pdf %>%
transmute(id, elenco = map(slug, get_elenco))O resultado é uma com uma list-column, assim:
| id | elenco |
|---|---|
| 1123 | c(“/elenco/fabio-porchat”, “/elenco/gregorio-duviver”) |
| 529 | c(“/elenco/antonio-tabet–2”, “/elenco/rafael-portugal”) |
| 826 | c(“/elenco/rafael-infant”, “/elenco/thati-lopes”) |
| 1151 | c(“/elenco/fabio-porchat”, “/elenco/gregorio-duviver”) |
| 814 | c(“/elenco/clarice-falcao”, “/elenco/julia-rabello”) |
Obtendo informações dos likes
Para acessar as informações dos likes, é necessário acessar a API do youtube. Acessar a API é fácil, mas é um pouco chato criar a chave de acesso. Para isso, sugiro seguir o tutorial abaixo:
api_key <- Sys.getenv("YOUTUBE_API")
baixar_dados <- function(video_id, api_key, dir) {
u_base <- "https://www.googleapis.com/youtube/v3/videos"
query <- list(id = video_id, key = api_key, part = "statistics")
r <- GET(u_base, query = query)
content(r, simplifyDataFrame = TRUE) %>%
pluck("items", "statistics") %>%
as_tibble()
}
# baixando os dados da API
da_api_pdf <- dados_site_pdf$video_id %>%
set_names() %>%
map_dfr(baixar_dados, api_key, path, .id = "video_id") %>%
mutate(video_id = path_ext_remove(basename(video_id))) %>%
clean_names() %>%
mutate_at(vars(ends_with("count")), as.numeric)Para este post, vamos usar só uma parte das informações obtidas, como quantidade de visualizações, elenco, título e data de publicação. A análise das descrições dos vídeos, likes e dislikes ficará para a próxima!
Arrumando a base final
Para analisar a quantidade de visualizações por elenco, precisamos juntar todas as bases e empilhar a partir da list-column criada. Nossa unidade amostral é vídeo-ator, então teremos várias repetições de ids. Também jogamos fora as colunas que não vamos utilizar e arrumamos os nomes dos atores com as funções arrumar_elenco() e arrumar_elenco_col()
arrumar_elenco <- . %>%
path_file() %>%
path_ext_remove() %>%
str_replace_all("[0-9-]", " ") %>%
str_squish() %>%
str_to_title()
arrumar_elenco_col <- . %>%
path_file() %>%
path_ext_remove() %>%
str_replace_all("[0-9-]", "_") %>%
str_replace_all("_+", "_") %>%
str_remove_all("_$") %>%
str_squish()
pdf_long <- da_elenco_pdf %>%
inner_join(da_site_pdf, "id") %>%
inner_join(da_api_pdf, "video_id") %>%
filter(!stringr::str_detect(slug, banned)) %>%
unnest(elenco) %>%
transmute(
id, title,
nome = arrumar_elenco_nm(elenco),
col = arrumar_elenco_col(elenco),
date = as.Date(ymd_hms(publish_date)),
view_count, like_count, dislike_count
)Visualizações
A primeira visualização que pensamos em fazer foi um gráfico da quantidade de visualizações acumulada ao longo do tempo, separando por artista. Vídeos que têm mais de um artista no elenco aparecem mais de uma vez no gráfico. É importante destacar que meu interesse não é analisar a quantidade média de visualizações dos artistas, e sim a quantidade total.
Montamos uma função grafico_acumulado() que mostra essa informação para artistas que possuem pelo menos n_corte= vídeos.
grafico_acumulado <- function(n_corte) {
da_plot <- pdf_long %>%
arrange(date) %>%
group_by(nome) %>%
mutate(n = n(), views = cumsum(view_count) / 1e6) %>%
ungroup() %>%
mutate(nome = fct_reorder(path_file(nome), views, .desc = TRUE)) %>%
filter(n >= n_corte)
# pega a ultima data de cada artista (para plot)
da_plot_last <- da_plot %>%
arrange(desc(date)) %>%
group_by(nome) %>%
slice(1) %>%
ungroup() %>%
mutate(last_date = max(date))
da_plot %>%
ggplot(aes(x = date, y = views, group = nome)) +
geom_step(colour = "darkred") +
ggrepel::geom_text_repel(
mapping = aes(label = nome, x = last_date),
data = da_plot_last,
hjust = 0, nudge_x = 20,
segment.size = .3,
direction = "y"
) +
geom_segment(
mapping = aes(x = date, xend = last_date, yend = views),
data = da_plot_last,
linetype = 2,
colour = "gray70"
) +
geom_point(aes(x = last_date), data = da_plot_last, size = 1) +
scale_x_date(
limits = c(min(d_plot$date), as.Date("2021-03-01")),
date_breaks = "1 year", date_labels = "%Y"
) +
theme_minimal(14) +
labs(
x = "Data", y = "Número total de visualizações (milhões)",
title = "Número acumulado de visualizações",
subtitle = stringr::str_glue("A partir do dia {format(min(d_plot$date), '%d/%m/%Y')}")
)
}O resultado de n_corte=70 é o que observamos na Figura 1. Podemos notar que os três sócios principais do PDF, Fabio Porchat, Gregorio Duvidier e Antonio Tabet dividem a liderança de visualizações em seus vídeos, seguidos pelo Rafael Portugal e Thati Lopes, que começaram a fazer vídeos mais recentemente.
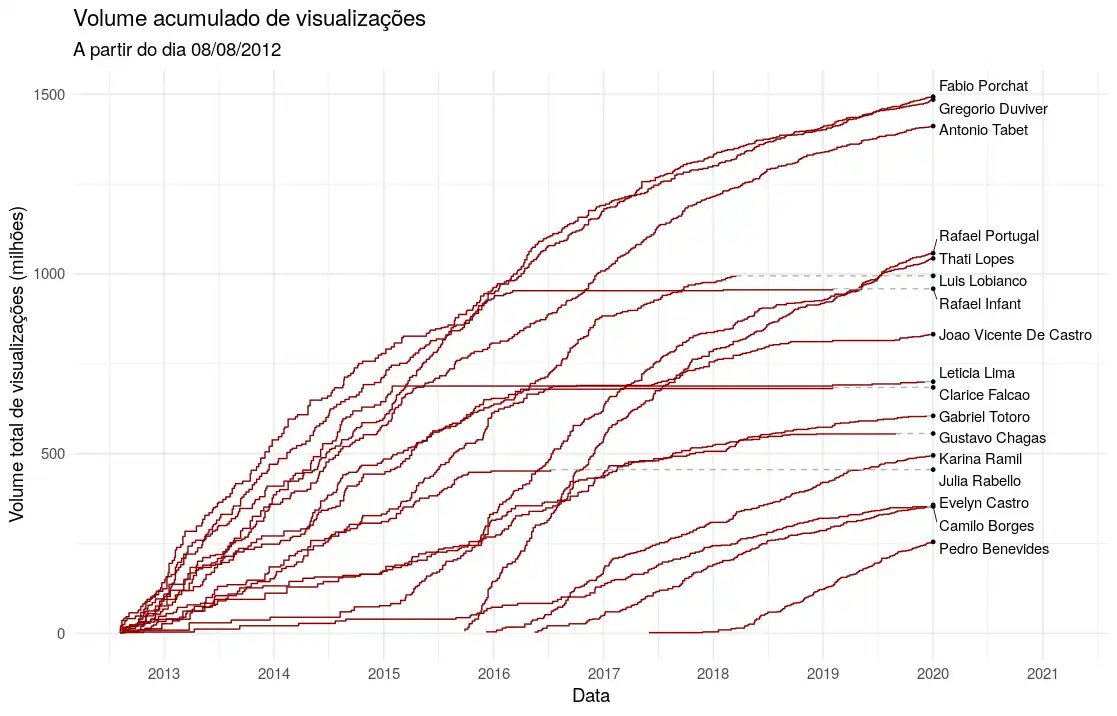
Figura 1: Gráfico do volume acumulado de visualizações por artista ao longo do tempo.
No entanto, sabemos que o porta dos fundos está em decadência. A Figura 2 mostra o mesmo gráfico do post feito lá em 2017 pelo William Amorim, mas com os dados atualizados. Aproveitei para adicionar os vídeos mais visualizados em cada ano.
pdf_long %>%
distinct(id, .keep_all = TRUE) %>%
mutate(view_count = view_count/1e6) %>%
ggplot(aes(x = date, y = view_count)) +
geom_line(alpha = .8) +
scale_x_date(date_breaks = "1 year", date_labels = "%Y") +
scale_y_continuous(limits = c(0, 40)) +
geom_text(aes(label = lab), data = max_ano, size = 3,
alpha = .8, vjust = -.2) +
geom_point(data = max_ano) +
theme_minimal(14) +
geom_smooth(se = FALSE, colour = "red") +
labs(x = "Data", y = "Visualizações (milhões)")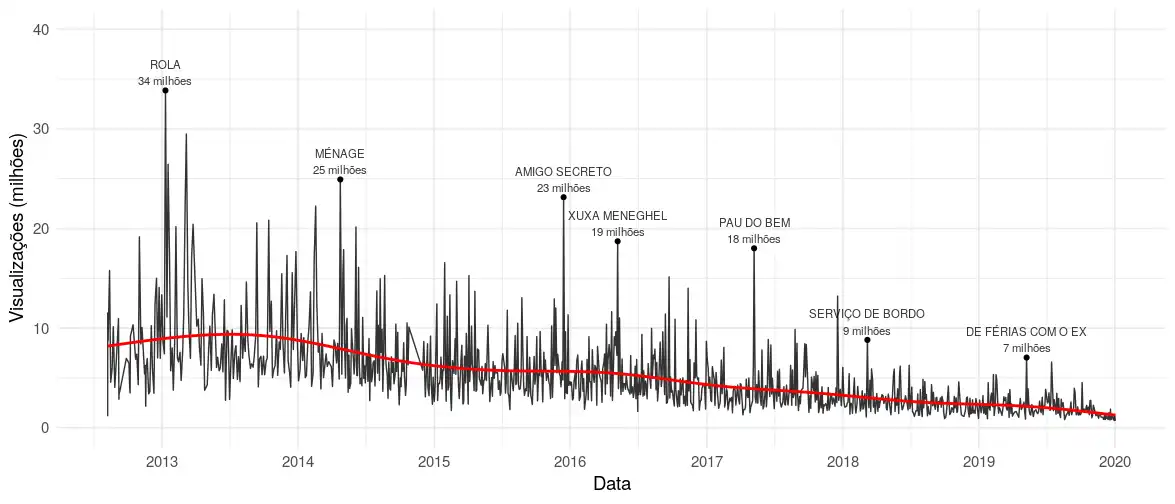
Figura 2: Volume de visualizações por vídeo por data de publicação.
É interessante notar também que a taxa de visualizações por quantidade de dias desde a publicação permanece constante, corroborando com a hipótese de que existe um efeito da idade do vídeo na quantidade de visualizações, formulada pelo Fernando mais de dois anos atrás. Aqui, consideramos apenas vídeos publicados até o final de 2018.
pdf_long %>%
distinct(id, .keep_all = TRUE) %>%
mutate(
idade = as.numeric(Sys.Date() - date),
tx = view_count / idade
) %>%
filter(date < "2019-01-01") %>%
ggplot(aes(x = date, y = tx)) +
geom_line() +
geom_smooth(se = FALSE, colour = "red") +
theme_minimal(14) +
labs(x = "Data", y = "Visualizações / # Dias desde publicação")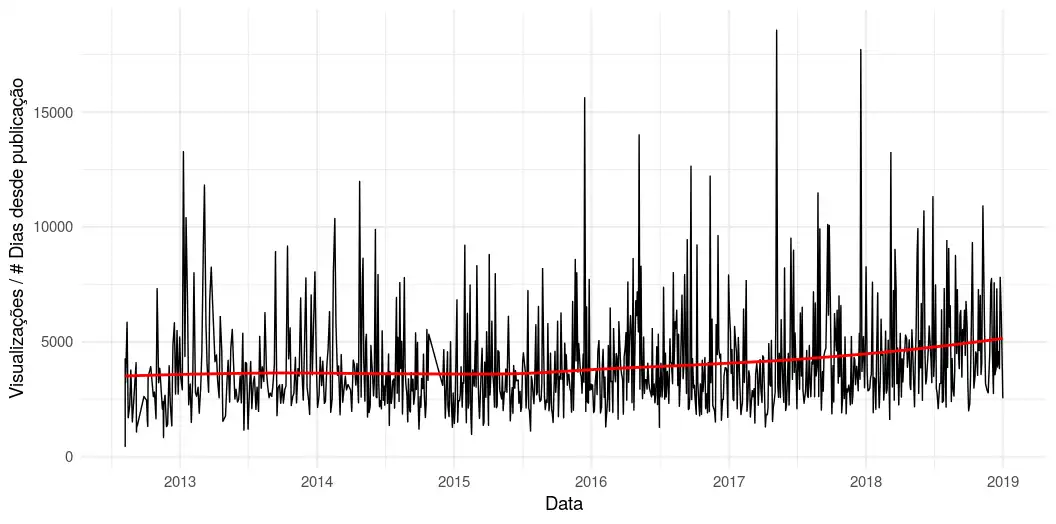
Figura 3: Taxa do volume de visualizações por quantidade de dias desde a publicação do vídeo.
Sendo assim, consideramos um novo gráfico com a quantidade de visualizações por artista considerando uma rolling window. Dessa forma, o passado prolífico do canal não afetará as conclusões sobre quem está carregando o PDF na atualidade. O resultado é a função grafico_roll(), que calcula a soma acumulada de acordo com uma janela especificada.
calcular_janela <- function(p_nm, p_dt, da_long) {
j <- p_dt - janela
da_long %>%
filter(nome == p_nm, between(date, j, p_dt)) %>%
summarise(view_count = sum(view_count)/1e6, n = n(), janela = j)
}
grafico_roll <- function(janela = lubridate::years(1), n_corte = 150) {
d_corte <- pdf_long %>%
group_by(nome) %>%
mutate(ntot = n()) %>%
ungroup() %>%
filter(ntot >= n_corte)
d_plot <- d_corte %>%
select(nome, date) %>%
mutate(roll = map2(nome, date, calcular_janela, d = d_corte)) %>%
unnest_legacy(roll) %>%
filter(!is.na(janela))
d_plot %>%
ggplot(aes(x = date, y = view_count, colour = nome)) +
geom_line() +
theme_minimal(14) +
facet_wrap(~nome)
}
grafico_roll(years(2), n_corte = 180)A Figura 4 mostra os resultados da análise considerando uma janela de 2 anos. Considerei no gráfico somente os 5 artistas com mais visualizações. Nesse gráfico é possível visualizar que Rafael Portugal está dominando as visualizações desde que entrou. No entanto, recentemente a diferença entre os cinco artistas está diminuindo. Uma explicação é que, como a quantidade de visualizações dos vídeos estacionou na média da Figura 2, as diferenças existentes entre os artistas passam a ser menos relevantes.
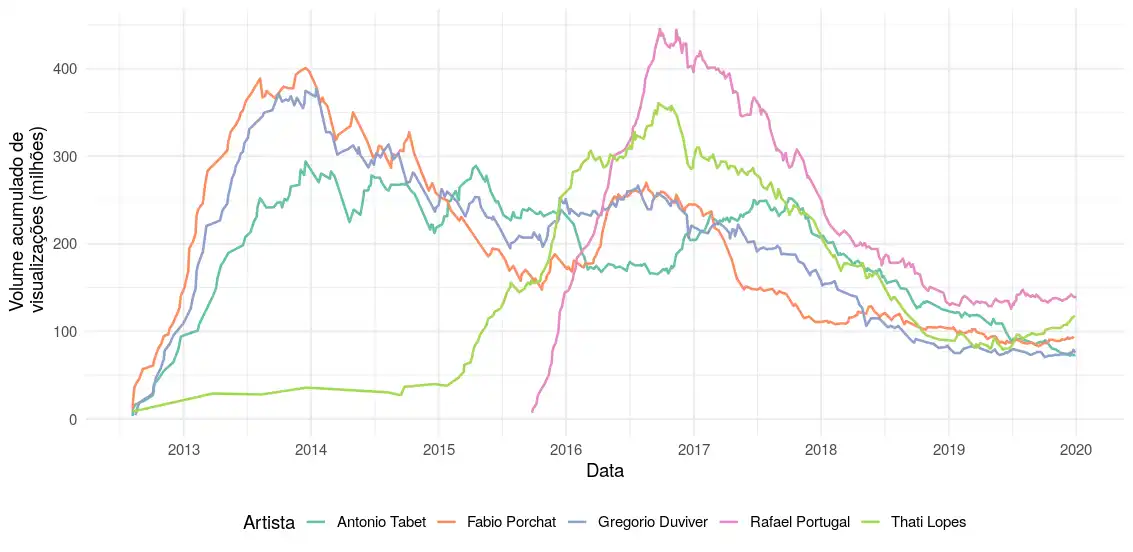
Figura 4: Gráfico do volume acumulado de visualizações por artista ao longo do tempo, considerando uma janela de 2 anos.
Ou seja, verifiquei minha hipótese, mas com um 🤷 no final.
É isso pessoal. Happy coding ;)


