O que faz o R ser tão legal é a comunidade que está por trás dela. Existem várias formas de acessar essa comunidade: pelo stackoverflow, twitter, facebook, entre outras. Nesse post vou falar um pouquinho sobre a comunidade RBrasil no telegram, usando dados!
A comunidade @rbrasiloficial foi criada em 2015 pelo Felipe Barros e já tem mais de mil inscritos. O canal é utilizado para tirar dúvidas, discutir sobre o futuro do R, divulgar trabalhos e dar pitacos sobre as coisas que estão acontecendo.
Nesse post vou mostrar como importar e arrumar os dados, e algumas visualizações da base de conversas do Telegram.
Importando os dados
O Telegram já possui uma ferramenta para exportar os chats. Basta clicar nas opções do chat e mandar exportar. Então vou assumir que esses dados já estão em mãos.
Os dados estão disponíveis no formato HTML. Para ler um arquivo, montei o seguinte código:
library(magrittr)
ler_html_telegram <- function(html_file) {
# pega todas as mensagens
divs <- xml2::read_html(html_file) %>%
xml2::xml_find_all("//div[@class='message default clearfix']")
# nome da pessoa
nomes <- divs %>%
xml2::xml_find_all("./div/div[@class='from_name']") %>%
xml2::xml_text() %>%
stringr::str_squish()
# data e hora da mensagem
data_horas <- divs %>%
xml2::xml_find_all("./div/div[@class='pull_right date details']") %>%
xml2::xml_attr("title") %>%
lubridate::dmy_hms()
# texto da mensagem
textos <- divs %>%
purrr::map(xml2::xml_find_first, "./div/div[@class='text']") %>%
purrr::map_chr(xml2::xml_text) %>%
stringr::str_squish()
# retorna numa tabela
tibble::tibble(
data_hora = data_horas,
nome = nomes,
texto = textos
)
}Depois, basta listar todos os arquivos e carregar cada arquivo usando purrr::map_dfr():
path <- "~/Downloads/Telegram Desktop/ChatExport_17_08_2019/"
todos_arquivos <- fs::dir_ls(path, regexp = "messages")
d_msg <- purrr::map_dfr(
todos_arquivos,
ler_html_telegram,
.id = "arquivo"
)No final, fiquei com uma base de dados com 26.980 linhas e 4 colunas.
Contas deletadas ganharam no volume de mensagens… Mas acho que não queremos considerá-las pois temos várias pessoas nessa contagem. O grande Marcelo Ventura Freire venceu no número de mensagens! Eu também estou no páreo :)
d_msg %>%
dplyr::count(nome, sort = TRUE) %>%
dplyr::mutate(prop = scales::percent(n/sum(n))) %>%
head(10) %>%
knitr::kable()| nome | n | prop |
|---|---|---|
| Deleted Account | 3101 | 11.5% |
| Marcelo Ventura Freire | 2313 | 8.6% |
| Charles Lula da Silva | 1897 | 7.0% |
| Leonard de Assis | 1677 | 6.2% |
| Sillas Gonzaga | 1540 | 5.7% |
| Julio Trecenti | 1130 | 4.2% |
| Bruna Wundervald | 951 | 3.5% |
| Andre Mesquita | 818 | 3.0% |
| Fernando Barbalho | 696 | 2.6% |
| George Santiago | 611 | 2.3% |
E no tempo, como que fica? Parece que no início o volume de mensagens era mais alto, e depois entramos num patamar estável.
library(ggplot2)
d_msg %>%
dplyr::mutate(mes = lubridate::floor_date(data_hora, "month")) %>%
dplyr::count(mes) %>%
ggplot(aes(x = mes, y = n)) +
geom_line() +
geom_point() +
theme_minimal(16)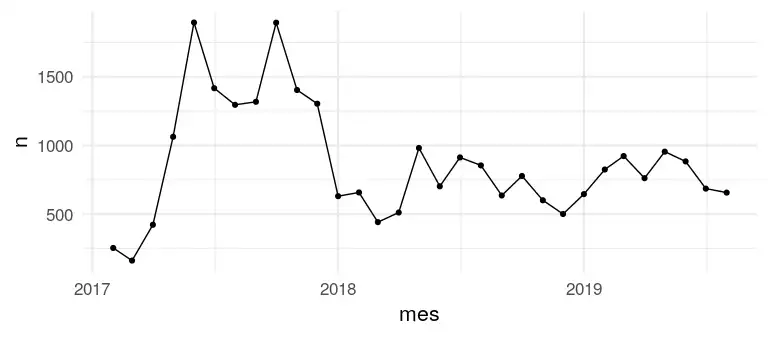
No gráfico seguinte, peguei as doze pessoas que falaram mais historicamente e avaliei a evolução mensal de mensagens. Temos de tudo: os constantes, os que sumiram, os que ressurgiram das cinzas e os que chegaram para ficar.
d_msg %>%
dplyr::filter(nome != "Deleted Account") %>%
dplyr::mutate(nome = forcats::fct_lump(nome, 12),
nome = as.character(nome),
mes = lubridate::floor_date(data_hora, "month")) %>%
dplyr::filter(nome != "Other") %>%
dplyr::count(mes, nome, sort = TRUE) %>%
tidyr::complete(mes, nome, fill = list(n = 0)) %>%
ggplot(aes(x = mes, y = n)) +
geom_line() +
facet_wrap(~nome) +
labs(x = "Mês", y = "Quantidade de mensagens") +
theme_bw()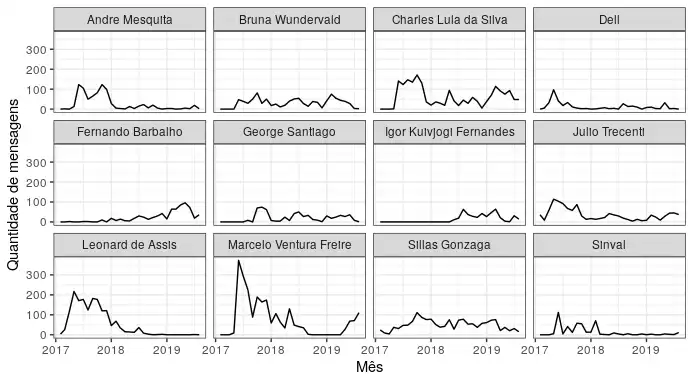
E qual é o horário que as pessoas interagem mais? Parece que é às 16 horas, aquele horário que a pessoa está ferrada no trabalho e precisa pedir uma ajuda aos amigos…
d_msg %>%
dplyr::mutate(hora = factor(lubridate::hour(data_hora))) %>%
ggplot(aes(x = hora)) +
geom_bar(fill = "royalblue") +
theme_minimal(14) +
ggtitle("Hora das mensagens")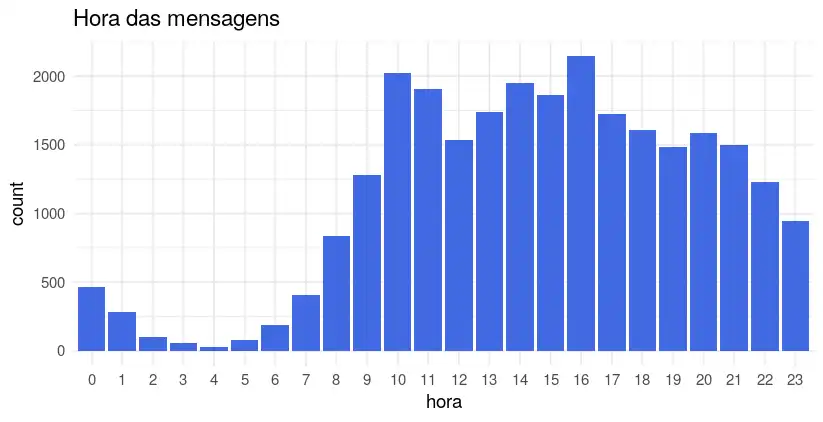
E o dia da semana? Terça-feira wins!
d_msg %>%
dplyr::mutate(wd = lubridate::wday(data_hora, label = TRUE)) %>%
ggplot(aes(x = wd)) +
geom_bar(fill = "pink2") +
theme_minimal(14) +
ggtitle("Dia da semana das mensagens")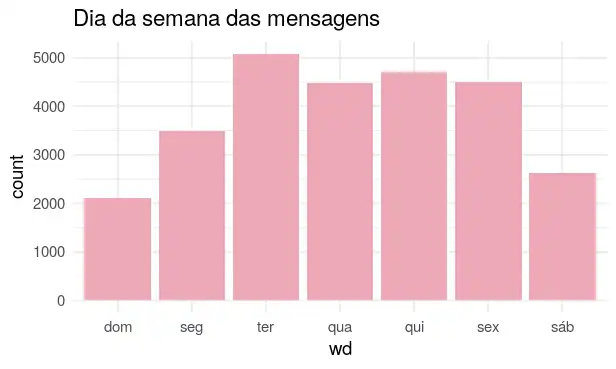
E claro, não poderia faltar um wordcloud…
# dá pra criar funções anônimas assim ;)
# esse é um limpador bem safado que fiz em 1 min
limpar <- . %>%
abjutils::rm_accent() %>%
stringr::str_to_title() %>%
stringr::str_remove_all("[^a-zA-Z0-9 ]") %>%
stringr::str_squish()
# tirar palavras que nao quero
banned <- tidytext::get_stopwords("pt") %>%
dplyr::mutate(palavra = limpar(word))
cores <- viridis::viridis(10, begin = 0, end = 0.8)
d_msg %>%
tidytext::unnest_tokens(palavra, texto) %>%
dplyr::mutate(palavra = limpar(palavra)) %>%
dplyr::anti_join(banned, "palavra") %>%
dplyr::count(palavra, sort = TRUE) %>%
with(wordcloud::wordcloud(
palavra, n, scale = c(5, .1),
min.freq = 80, random.order = FALSE,
colors = cores
))
Fiz poucos gráficos para te deixar com vontade de brincar mais. Gostou da brincadeira? Então faça suas próprias análises do seu chat preferido do Telegram!
É isso. Happy coding ;)


