Uma forma poderosa de participar socialmente é utilizando dados abertos. Dados abertos tornam a sociedade mais democrática pois com eles podemos verificar afirmações baseadas em estatísticas e também buscar novas narrativas para os fenômenos estudados.
Nesse post, mostramos um exemplo de como isso pode ser feito, utilizando os dados da Sistema Nacional de Informações de Segurança pública, o SINESP. O objetivo com esse texto é empoderar as pessoas que trabalham com ciência de dados e mostrar como podemos participar socialmente usando o R.
No dia 16/julho o Ministro da Justiça, Sérgio Moro, fez a seguinte declaração no Twitter:
Abaixo notícia de verdade. Dados do Sinesp, estes, sim, oficiais, apontam queda no primeiro trimestre de 2019 do número dos principais crimes em todo o país em comparação com o mesmo período de 2018. Vamos trabalhar para aprofundar essa queda e levar segurança a cada cidadão. pic.twitter.com/srnJZF4X6K
— Sergio Moro (@SF_Moro) July 16, 2019
O legal de existirem dados abertos é que podemos checar esses informações e criar análises mais aprofundadas sobre o tema. Infelizmente, ainda não foram disponibilizados os dados do primeiro bimestre de 2019, que fazem parte do Tweet do Moro.
Mas isso não é um problema, pois podemos fazer diversos cruzamentos com os dados que estão disponíveis. Nesta rápida análise, mostro como baixar os dados a partir do portal de dados abertos https://dados.gov.br. Para isso, utilizarei o tidyverse, httr e xml2.
library(tidyverse)Parte 1: Download
Como o dados.gov.br é um portal muito bem feito, é possível baixar todos os dados em CSV com um pipeline simples:
# caminho do diretório
path_sinesp <- "~/data-raw/sinesp/"
# cria o diretório
fs::dir_create(path_sinesp)
# link do SINESP no dados.gov.br
u_sinesp <- paste0("http://dados.gov.br/dataset",
"/sistema-nacional-de-estatisticas-de-seguranca-publica")
u_sinesp %>%
# carrega a página
httr::GET() %>%
# parseia o código fonte da página
xml2::read_html() %>%
# identifica todas as tags que contêm os links
xml2::xml_find_all("//ul[@class='dropdown-menu']//a") %>%
# extrai a lista todos os links
xml2::xml_attr("href") %>%
# seleciona apenas os arquivos xlsx da lista
str_subset("xlsx") %>%
# essa parte faz o loop de download. Demora ~1 minuto
walk(~httr::GET(.x, httr::write_disk(paste0(path_sinesp, basename(.x)))))Nada impede o usuário de baixar esses arquivos CSV manualmente. Pode ser até que seja mais rápido baixar manualmente se for uma vez só. A vantagem desse código é que ele é reprodutível, a menos que o site mude sua estrutura. Ou seja, quando chegarem os dados de 2019, provavelmente poderemos baixar tudo novamente usando o mesmo código.
Parte 2: Importação e arrumação
O código abaixo carrega e arruma os dados para análise. Sempre existem inconsistências nos dados e devemos ficar atentos a eles.
d_sinesp <- path_sinesp %>%
# lista os arquivos
fs::dir_ls() %>%
# lê todos os arquivos xlsx e empilha
map_dfr(readxl::read_excel, col_types = "text", .id = "file") %>%
# define os nomes das colunas
set_names(c("file", "uf", "tipo_crime", "mes_ano", "valor")) %>%
# transforma os valores para os tipos corretos
transmute(
uf,
# transformando string em data
mes_ano = lubridate::dmy(paste0("01/", mes_ano)),
# arrumando tipo de crime
tipo_crime = str_to_title(tipo_crime),
valor = as.numeric(valor),
# cria uma coluna com o bimestre
bimestre = lubridate::floor_date(mes_ano, "bimonth")
)No caso, o maior problema era um tipo de crime que estava escrito com nomes ligeiramente diferentes. Um stringr::str_to_title() foi suficiente para resolver. A base de dados ficou assim:
| uf | mes_ano | tipo_crime | valor | bimestre |
|---|---|---|---|---|
| Acre | 2015-01-01 | Estupro | 6 | 2015-01-01 |
| Acre | 2015-01-01 | Furto De Veículo | 0 | 2015-01-01 |
| Acre | 2015-01-01 | Homicídio Doloso | 13 | 2015-01-01 |
| Acre | 2015-01-01 | Lesão Corporal Seguida De Morte | 0 | 2015-01-01 |
| Acre | 2015-01-01 | Roubo A Instituição Financeira | 0 | 2015-01-01 |
| Acre | 2015-01-01 | Roubo De Carga | 0 | 2015-01-01 |
| Acre | 2015-01-01 | Roubo De Veículo | NA | 2015-01-01 |
| Acre | 2015-01-01 | Roubo Seguido De Morte (Latrocínio) | 0 | 2015-01-01 |
| Acre | 2015-01-01 | Tentativa De Homicídio | 2 | 2015-01-01 |
| Acre | 2015-02-01 | Estupro | 8 | 2015-01-01 |
Parte 3: Transformação
Nesse código, meu objetivo foi reproduzir a tabela do Ministro da Justiça, mas adicionando as mudanças ocorridas entre 2015-2016, 2016-2017 e 2017-2018. Não fiz a análise por trimestre, e sim por bimestre. O leitor interessado pode replicar as análises para trimestres.
results <- d_sinesp %>%
# agrupa por bimestre e sumariza
group_by(bimestre, tipo_crime) %>%
summarise(valor = sum(valor, na.rm = TRUE)) %>%
ungroup() %>%
# apenas primeiro bimestre e tirar dados de antes de 2015
filter(lubridate::month(bimestre) == 1,
lubridate::year(bimestre) >= 2015) %>%
# ordenar e agrupar por tipo de crime
arrange(tipo_crime, bimestre) %>%
group_by(tipo_crime) %>%
# adicionar bimestre anterior
mutate(vl_lag = lag(valor)) %>%
ungroup() %>%
# tirar 2015
filter(!is.na(vl_lag)) %>%
# calcula a razão
mutate(razao = scales::percent(valor / vl_lag - 1),
bim1 = lubridate::year(bimestre)) %>%
# seleciona as colunas importantes
select(bim1, tipo_crime, razao) %>%
# joga os bimestres nas colunas
spread(bim1, razao, sep = "_")
knitr::kable(results)| tipo_crime | bim1_2016 | bim1_2017 | bim1_2018 |
|---|---|---|---|
| Estupro | 4.3% | 1.2% | 11.5% |
| Furto De Veículo | 5.5% | -7.3% | -6.4% |
| Homicídio Doloso | 3.3% | 6.5% | -10.6% |
| Lesão Corporal Seguida De Morte | 21.6% | 23.0% | -7.8% |
| Roubo A Instituição Financeira | -4.8% | -28.9% | -1.4% |
| Roubo De Carga | -1.5% | 13.1% | 11.2% |
| Roubo De Veículo | 9.8% | 7.0% | -5.9% |
| Roubo Seguido De Morte (Latrocínio) | 12.5% | 13.7% | -13.1% |
| Tentativa De Homicídio | -7.7% | -2.0% | -9.9% |
A tabela mostra que o primeiro bimestre de 2018, se comparado ao de 2017, também apresenta quedas em todos os tipos de crime, com exceção de estupro e roubo de cargas. Além disso, como será possível ver no próximo gráfico, as variações percentuais acima de 20% na tabela ocorrem em crimes com pequeno volume absoluto de ocorrências. Isso é esperado, pois quando o valor absoluto é pequeno, pequenas mudanças podem significar grandes variações percentuais. Por exemplo, se uma contagem vai de 150 para 120 (queda de 30), a queda é de 20%, mas se outra contagem vai de 1000 para 900 (queda de 100), a queda percentual é de 10%
Parte 4: Visualização
Nesse gráfico, mostrei a série bimestral de ocorrências por tipo de crime, buscando identificar tendências de subida ou queda.
d_sinesp %>%
# soma por bimestre e tipo de crime
group_by(bimestre, tipo_crime) %>%
summarise(valor = sum(valor, na.rm = TRUE)) %>%
ungroup() %>%
# apenas 2015 para frente
filter(lubridate::year(bimestre) >= 2015) %>%
# monta o grafico
ggplot(aes(x = bimestre, y = valor)) +
# adiciona linhas
geom_line() +
# adiciona uma linha vertical par 2018
geom_vline(xintercept = as.Date("2018-01-01"), colour = "red", linetype = 2) +
# divide o grafico por tipo de crime
facet_wrap(~tipo_crime, scales = "free_y", ncol = 3) +
theme_bw()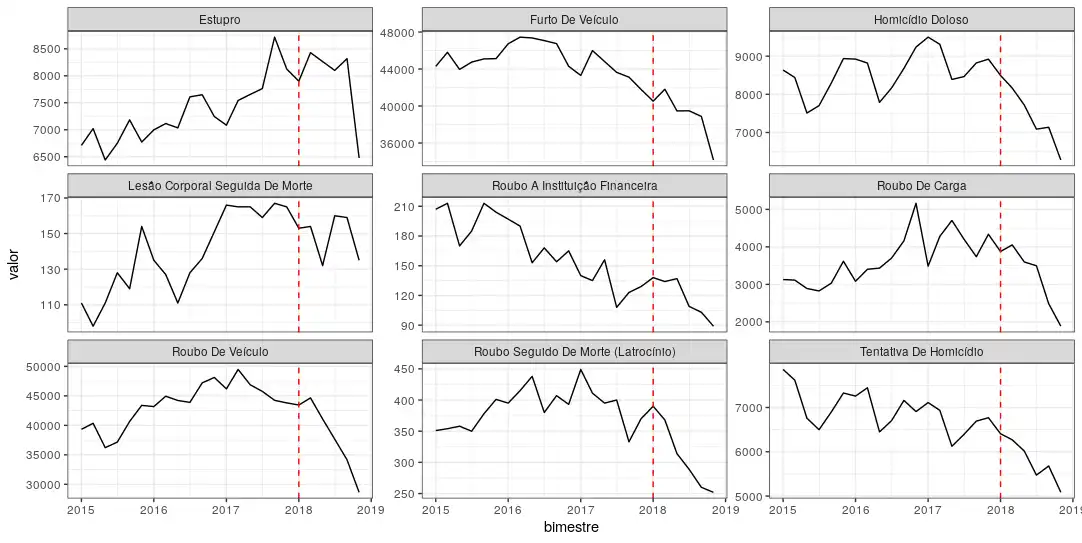
Pelo gráfico, é possível identificar que, em diversos tipos de crime, existe uma tendência de queda após o primeiro bimestre de 2018. Ou seja, não se pode atribuir a queda nas estatísticas de ocorrências ao novo governo de 2019. A queda vertiginosa no volume de estupros é bem curiosa.
Wrap-up
- Dado aberto é a melhor forma de tornar as informações disponibilizadas publicamente auditáveis.
- Com o R, é fácil ingerir esses dados para realizar análises simples e complexas.
- Não se engane: dado aberto não é dado arrumado. O trabalho de faxina de dados é contínuo.
É isso. Happy coding ;)


