Esse é um post de matemática. Mesmo se você não curte essa faceta da ciência de dados, encorajo vocês a lerem e estudarem esse assunto. Nesse texto vou usar um pouco de teoria dos conjuntos e introduzir a teoria da medida, que é a base matemática de tudo que sabemos sobre probabilidade.
Aos matemáticos: eu tentei simplificar ao máximo a linguagem, então posso ter cometido alguns deslizes. Não sou o Billingsley, então não peço desculpas! ;)
Objetivo
Nosso objetivo é definir matematicamente a função probabilidade. Isso é diferente de definir a interpretação da probabilidade, como a interpretação frequentista e subjetivista, que é assunto para outro texto.
Pra quê? Durante meus estudos, o argumento mais comum usado para me convencer a estudar probabilidade e medida foi: se você constrói toda a estatística – e consequentemente boa parte da ciência – a partir de um objeto matemático, é bom que esse objeto esteja bem definido e funcione direito, né!? Mas nós sabemos que ele está bem definido, pois já disseram isso pra gente em algum momento no passado. Devem ter várias pessoas que já se preocuparam com isso, então deve funcionar!
Por isso, eu vou te dar outro argumento: se algum dia você montar um novo modelo estatístico e quiser mostrar que ele prevê bem em bases de dados diferentes da sua, você precisará extrair algumas propriedades do seu modelo. E para extrair essas propriedades, você precisará manjar de probabilidade no nível de medida.
Não adianta você ser dono de uma padaria, contratar um padeiro e não saber fazer pão. Um dia seu padeiro vai faltar e você estará ferrado.
– WUNDERVALD, J.
É difícil? SIM! A definição de probabilidade seria muito simples e intuitiva se não fossem algumas dificuldades associadas ao conjunto dos números reais \(\mathbb R\), e o fato deles serem não contáveis1. Por isso, convido vocês a entrarem comigo nessa jornada com os seguintes passos:
- Tentar definir a probabilidade intuitivamente.
- Verificar que essa definição tem problemas.
- Tirar da cachola uma tal de \(\sigma\)-álgebra que, em tese, resolve (2).
- Mostrar que ela de fato resolve (2), mostrando mais um conjunto tirado da cachola: o conjunto dos mensuráveis.
- Mostrar que \(\sigma\)-álgebras são difíceis de trabalhar.
- Mostrar que tem uma forma de trabalhar (5) sem nos deixar o cabelo em pé, graças ao nosso amigo Caratheodory.
Definindo a probabilidade com intuição
Probabilidade nada mais é que medir eventos, soltando números entre zero e um. Mas o que são eventos, e o que é medir?
O exemplo mais fácil de medida que consigo pensar é a régua. A régua é uma função \(\lambda(\cdot)\) que recebe como input um intervalo \((a,b]\) e retorna \(b-a\). Ou seja, a função de medida é uma função que trabalha com conjuntos e retorna números reais não-negativos. Mas \(b-a\) pode ser maior que um, ou até infinito. Logo, a probabilidade é um caso particular de medida, que recebe como input um conjunto e como output um número no intervalo \([0,1]\).

No caso da régua, daria para resolver isso forçando \(0 \leq a < b \leq 1\). Assim todos os intervalos teriam medida entre zero e um. De fato, quando trabalhamos com variáveis aleatórias
No entanto, nem tudo na vida são intervalos na reta. Queremos poder calcular probabilidade de chover amanhã, ou então a probabilidade de um cliente ficar inadimplente após 100 dias ou mais. Para isso, precisamos definir um conjunto abstrato \(\Omega\), que chamamos de espaço amostral. Esse carinha contém os eventos individuais que estamos interessados, e calculamos probabilidades sobre combinações de pedaços dele.
Essas combinações de pedaços (ou subconjuntos) de \(\Omega\) são os eventos. Por exemplo, no caso da chuva \(\Omega\) seria \(\{\text{chover},\text{não chover}\}\) e calculamos probabilidades sobre \(\{\text{não chover}\}\), \(\{\text{chover}\}\), \(\{\text{não chover}\} \text{ ou } \{\text{chover}\}\), e o vazio \(\emptyset\). No caso da inadimplência, nosso \(\Omega\) poderia ser os naturais \(\mathbb N\), por exemplo, e o evento de interesse seria \(\{i\in \mathbb N: i \geq 100\}\).
Primeiro, defina como \(\mathcal P(\Omega)\) como o conjunto de todos os eventos baseados em \(\Omega\). Chamamos esse objeto de partes de \(\Omega\). Esse cara é bem grande, pois tem não só o próprio \(\Omega\) e o vazio \(\emptyset\), como também todas as possíveis combinações de subconjuntos do \(\Omega\). No caso da chuva, são apenas os quatro eventos citados no parágrafo anterior. No caso da inadimplência, temos todos os números naturais e ainda todas as combinações desses números. No caso da régua então, temos desde o intervalo \((0, \frac \pi 4]\) até o conjunto de Cantor, o que pode ser bem infinito!
Segundo, uma propriedade desejável da probabilidade é a aditividade. Ela significa que se eu tiver em mãos dois eventos disjuntos (ou seja, com interseção vazia), a probabilidade de algum desses eventos ocorrer é igual à soma das probabilidades de cada um desses eventos. Essa é uma suposição bem intuitiva no caso da régua. Se você pegar dois intervalos separados de uma reta e medir os dois intervalos de uma vez, isso será equivalente a medir cada um dos intervalos e depois somar. Curiosamente, existem áreas grandes da matemática/estatística que trabalham com medidas que não seguem essa regra. Veja, por exemplo, a medida de possibilidade.
Agora estamos prontos para definir a medida de probabilidade. Queremos uma função \(\mathbb P(\cdot)\) que tenha as seguintes características:
- Recebe um elemento de \(\mathcal P(\Omega)\) e retorna um número real não-negativo.
- (Normalização) \(P(\Omega) = 1\). Isso obriga a probabilidade a ficar sempre entre zero e um, pois nada tem medida maior que \(\Omega\).
- (Aditividade) Para a sequência \(A_j\), \(j \in \mathbb N\), com \(A_j \cap A_k = \emptyset\) (disjuntos) para todo \(j\) e \(k\), vale \(\mathbb P(\cup_j A_j) = \sum_j \mathbb P(A_j)\).
Note que, se você pensar que \(\cup_j A_j\) é como uma soma dos \(A_j\), a propriedade (3) é o que permite “passar a soma para fora” da probabilidade.
Note também que eu coloquei aí uma união infinita e contável. Alguns pesquisadores gostam de restringir a medida de probabilidade para uniões finitas apenas. Isso ajuda bastante na parte matemática, mas pode levar a alguns problemas práticos. Isso gerou uma treta enorme entre os matemáticos: leia aqui para uma abordagem histórica do tema. No final, a versão mais popular é a com uniões infinitas.
Muito bem, esses são os famosos Axiomas de Kolmogorov! Ou quase…
O problema de usar as partes como a base de tudo
Eu comentei alguns parágrafos atrás que a coleção \(\mathcal P(\Omega)\) pode ser um objeto muito infinito. O problema é que esse conjunto pode ser tão, mas tão grande, que pode bugar a função de probabilidade. Um exemplo famoso de bug se chama conjunto de Vitali: a medida desse evento leva a uma contradição.
Para explicar esse conjunto, vamos voltar à medida régua \(\lambda\), sem restringir ao zero e um. A régua tem mais uma propriedade interessante: se \(x\in \mathbb R\), o conjunto transladado \(x+A\), ou seja, o conjunto formado por todos os elementos de \(A\) somados de \(x\), tem a mesma medida que \(A\). Por exemplo, se \(A = (a,b]\), então \(A+x = (a+x,b+x]\), e a medida desse conjunto é
\[\lambda(A+x) = \lambda((a+x,b+x]) = (b+x)-(a+x) = b-a = \lambda(A).\]
Agora vamos ao exemplo de conjunto não mensurável. O exemplo é um caso de matemágica, ou seja, é bem complicado tirar a intuição dele. Além disso, esse exemplo usa diretamente o axioma da escolha. Mas tudo bem, é um exemplo, e vamos ver que ele funciona.
Passo 1. Para cada \(x \in \mathbb R\), defina \([x] = \{y\in \mathbb R, y-x \in \mathbb Q\}\). Ou seja, para cada \(x\) criamos um subconjunto de \(\mathbb R\) que contém todos os números que subtraídos de \(x\) são racionais. Por exemplo, se \(x = \sqrt 2\), \([x] = \{\sqrt 2, 2\sqrt 2, \dots\}\) (são muitos casos possíveis). Defina o conjunto de todos os possíveis \([x]\) de \(\Lambda\). ou seja, \(\Lambda\) é o conjunto dos conjuntos \([x]\), e cada elemento \(\alpha \in \Lambda\) é um conjunto que contém uma porção de números reais.
Passo 2. Note que para cada conjunto \(\alpha \in \Lambda\), sempre existe um elemento \(a \in \alpha\) que está no intervalo \((0,1)\). Agora, para cada \(\alpha \in \Lambda\), pegamos um elemento \(a_\alpha \in \alpha\) que está no intervalo \((0,1)\). Finalmente, chamamos \(\Omega\) de todos esses conjuntos \(a_\alpha\), e temos \(\Omega \subseteq (0,1)\). Numa imagem:
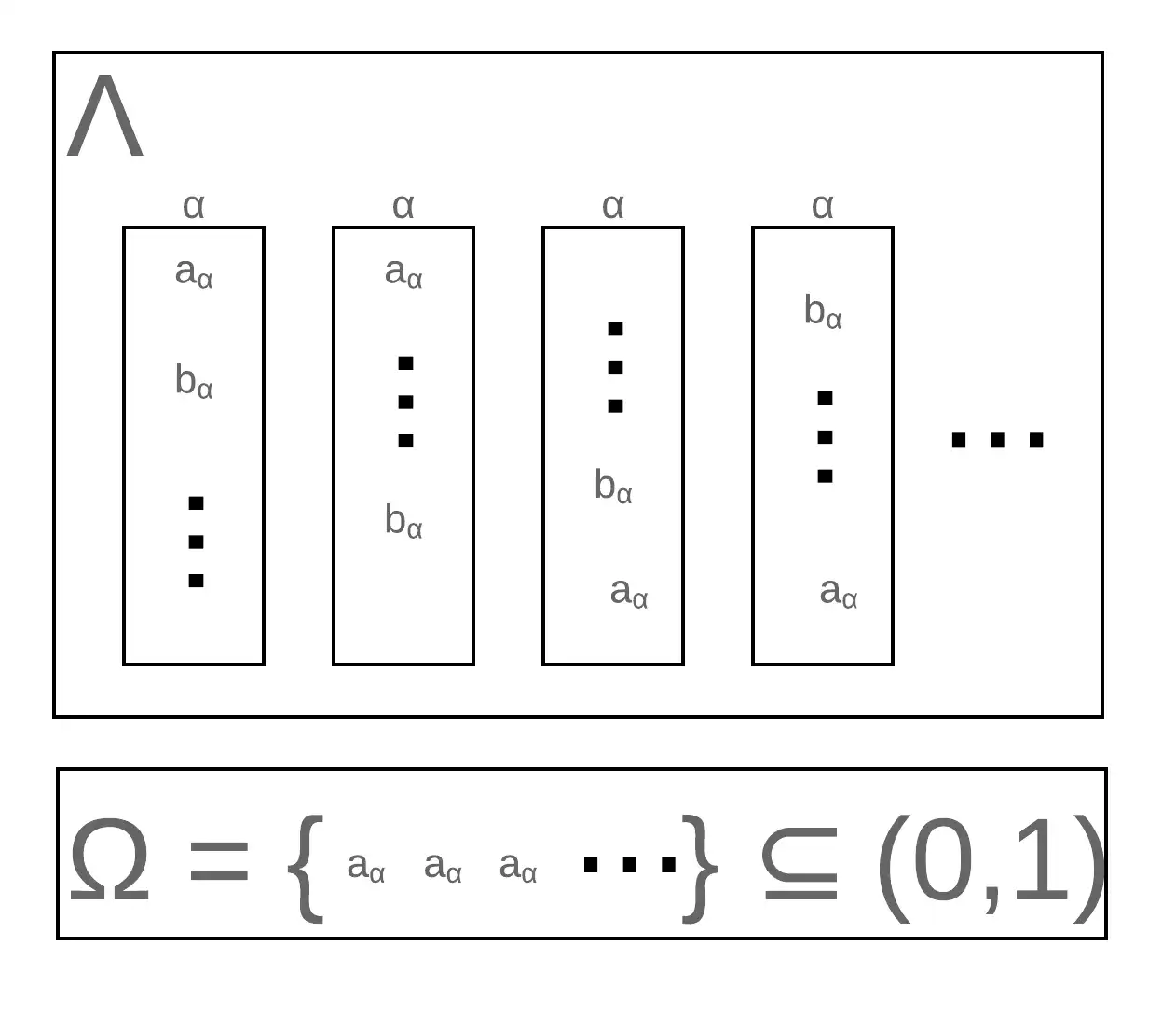
Muito bem. Agora, note que se \(p,q \in \mathbb Q\), então \((\Omega+q)\) e \((\Omega+p)\) são disjuntos. Na verdade, se não fossem disjuntos, isso significaria que \(p=q\) e os conjuntos coincidiriam. Isso acontece porque, se \(x \in (\Omega+q)\cap (\Omega+p)\), então \(x\) é um elemento dos dois conjuntos:
\[x = a+p = b+q \implies b-a=q-p\]
Como \(q-p\) é racional, então \(b-a\) é racional, logo \(b \in [a]\). Mas nós montamos \(\Omega\) com apenas um elemento de cada conjunto \([a]\) como esse, então \(a=b\). Logo, \(p=q\).
Agora, vamos às contas. Estamos interessados em calcular, para \(-1<p<1\), \(p \in \mathbb Q\), a medida
\[ \lambda\left(\bigcup_{p} (\Omega + p)\right) \]
Por um lado, temos que \(\bigcup_{p} (\Omega + p) \subseteq(-1,2)\). Então,
\[ \lambda\left(\bigcup_{p} (\Omega + p)\right) \leq \lambda((-1, 2]) = 3. \]
Por outro lado, como os \((\Omega + p)\) são disjuntos, temos
\[\lambda\left(\bigcup_{p} (\Omega + p)\right) = \sum_p\lambda(\Omega+p) = \sum_p\lambda(\Omega)\]
Como estamos somando várias vezes o mesmo termo, e como a soma deve ser menor ou igual a 3, então temos que \(\lambda(\Omega) = 0\). Logo,
\[ \lambda\left(\bigcup_{p} (\Omega + p)\right) = 0. \]
E agora vem o problema. Para \(x \in (0,1)\), temos que existe um \(a \in [x]\) que está em \(\Omega\), certo? E sabemos também que esse \(a \in (0,1)\), porque definimos assim. Como \(a \in [x]\), então \(p^* = a - x\) é racional. Além disso, \(-1<p^*<1\), por conta dos valores de \(a\) e \(x\). Logo, \(x = a + p\), onde \(p=-p^*\), então \(x \in (\Omega + p)\). Como isso vale para todo \(x \in (0,1)\), temos que
\[(0,1) \subseteq \bigcup_{p} (\Omega + p)\] Logo,
\[\lambda\left(\bigcup_{p} (\Omega + p)\right) \geq \lambda((0,1)) = 1\]
Ué, mas um número não pode ser zero e maior ou igual a um ao mesmo tempo. Isso é uma contradição. Logo, como encontramos problemas em elementos de \(\mathcal P(\Omega)\), não podemos definir a probabilidade nesse conjunto.
A solução: \(\sigma\)-álgebras
Uma \(\sigma\)-álgebra \(\mathcal F\) é um conjunto de subconjuntos, como as partes, mas um pouco menor. Ela tem condições restritivas restritivas:
- \(\Omega \in \mathcal F\)
- se \(A \in \mathcal F\), então \(A^c \in \mathcal F\).
- se \(A_j \in \mathcal F, j\in \mathbb N\), então \(\cup_j A_j \in \mathcal F\).
[este post ainda não está finalizado. Volte depois…]
Um conjunto contável \(A\) é um conjunto que podemos mapear nos naturais \(\mathbb N\). Ou seja, \(A\) é contável se conseguirmos montar uma função que associe cada elemento \(a \in A\) a um novo elemento \(n \in \mathbb N\). Por exemplo, o conjunto dos inteiros \(\mathbb I\) é contável, pois, podemos montar uma função que mapeia os números positivos nos naturais pares e os negativos nos naturais ímpares. Outro exemplo de conjunto contável são os racionais \(\mathbb Q\). Um conjunto não contável são os irracionais (aquele que tem \(\pi\), \(e\), \(\sqrt 2\), etc) e o conjunto dos reais \(\mathbb R\), já que ele contém os irracionais. Vamos:↩︎


