Modelos baseados em árvores como árvores de decisão, random forest, ligthGBM e xgboost são conhecidos, dentre outras qualidades, pela sua robustês diante do problema de multicolinearidade. É sabido que seu poder preditivo não se abala na presença de variáveis extremamente correlacionadas.
Porém, quem nunca usou um Random Forest pra fazer seleção de variáveis? Pegar, por exemplo, as top 10 mais importantes e descartar o resto?
Ou até mesmo arriscou uma interpretação e concluiu sobre a ordem das variáveis mais importantes?
Abaixo mostraremos o porquê não devemos ignorar a questão da multicolinearidade completamente!
Um modelo bonitinho
Primeiro vamos ajustar um modelo bonitinho, livre de multicolinearidade. Suponha que queiramos prever Petal.Length utilizando as medidas das sépalas (Sepal.Width e Sepal.Length) da nossa boa e velha base iris.
library(tidyverse)
## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.0 ──
## ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
## ✓ tibble 3.0.4 ✓ dplyr 1.0.2
## ✓ tidyr 1.1.2 ✓ stringr 1.4.0
## ✓ readr 1.4.0 ✓ forcats 0.5.0
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
iris2 <- iris %>% select(Sepal.Length, Sepal.Width, Petal.Length)
iris2 %>% cor %>% corrplot::corrplot()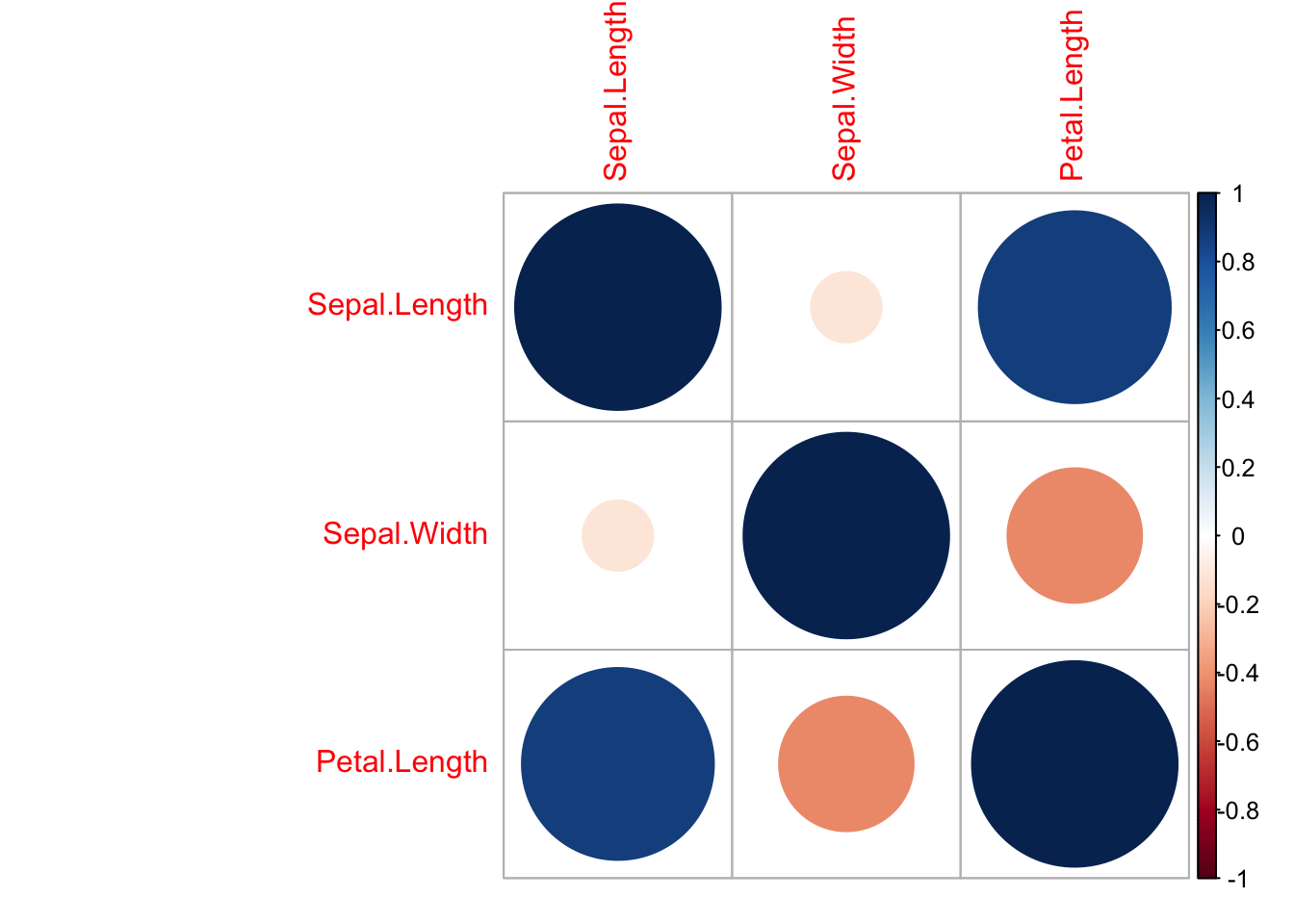
O gráfico acima mostra que as variáveis explicativas não são fortemente correlacionadas. Ajustando uma random fores, temos a seguinte ordem de importância das variáveis:
library(randomForest)
iris2_rf <- randomForest(Petal.Length ~ ., data = iris2)
varImpPlot(iris2_rf)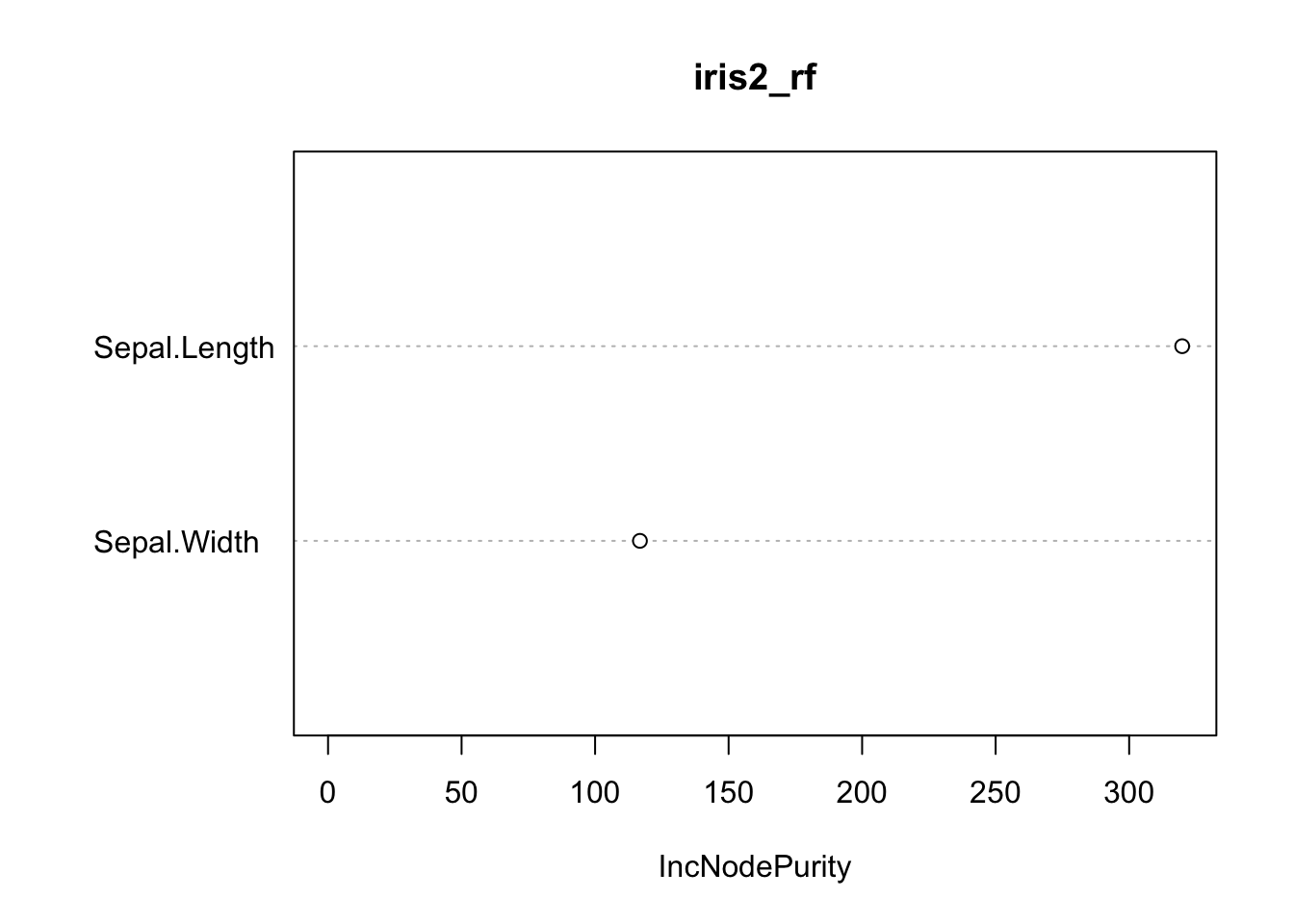
Sem surpresas. Agora vamos para o problema!
Um modelo com feinho
Vamos forjar uma situação extrema em que muitas variáveis sejam multicolineares. Vou fazer isso repetindo a coluna Sepal.Length várias vezes.
iris3 <- accumulate(1:20, ~{
.x[[paste0("Sepal.Length", .y)]] <- iris2$Sepal.Length
.x
}, .init = iris2)
iris3[[20]] %>% cor %>% corrplot::corrplot(order = "alphabet")
Agora a coisa tá feia! Temos 20 variáveis perfeitamente colineares. Mesmo assim um random forest nessa nova base não perderia poder preditivo.
Mas como ficou a importância das variáveis?
iris3_rf <- randomForest(Petal.Length ~ ., data = iris3[[20]])
varImpPlot(iris3_rf)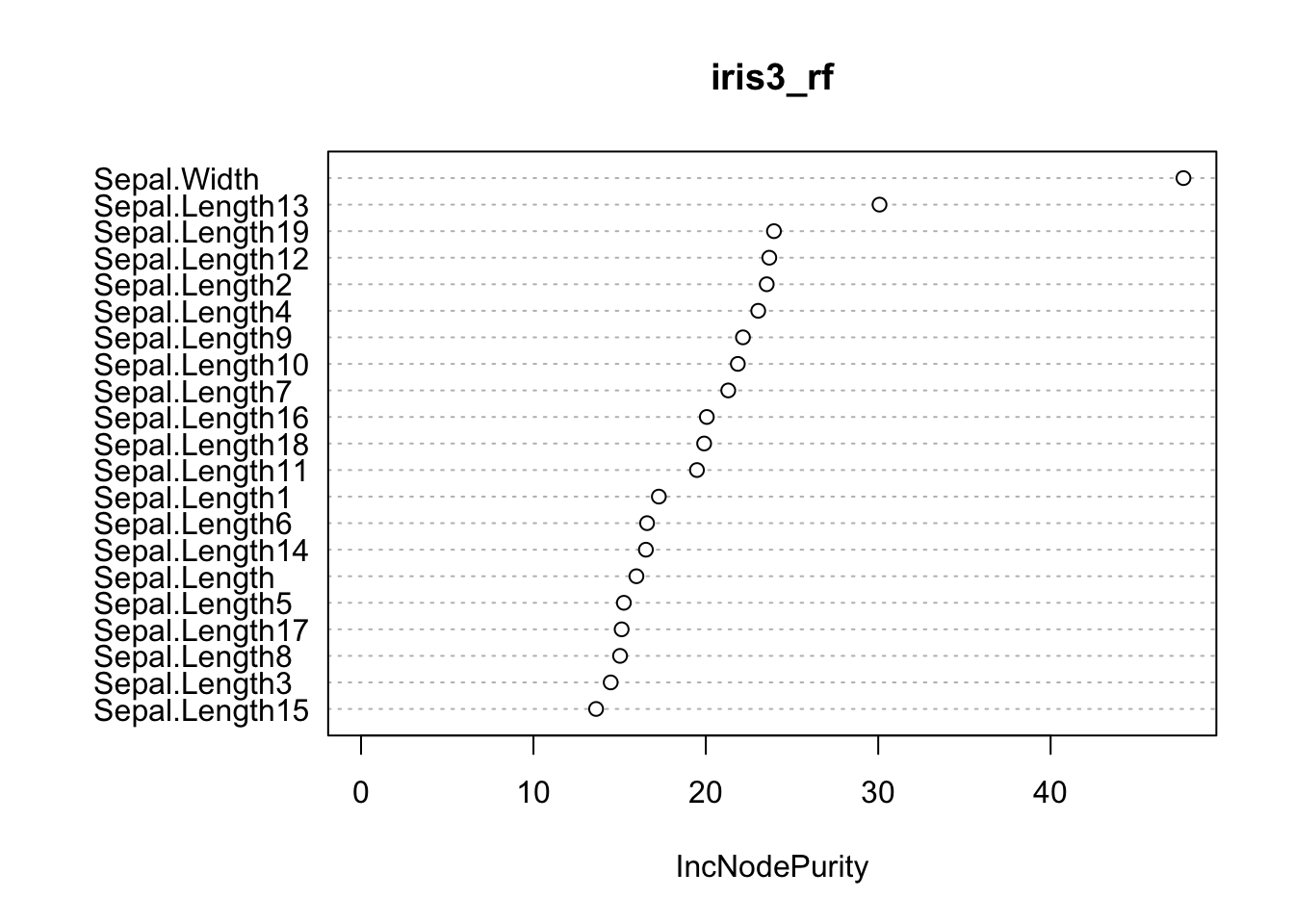
Aqui o jogo já se inverteu: concluiríamos que Sepal.Width é mais importante de todas as variáveis!
Seleção de variáveis furado
O gráfico abaixo mostra que quanto mais variáveis correlacionadas tivermos, menor a importância de TODAS ELAS SIMULTANEAMENTE! É como se as variáveis colineares repartissem a importância entre elas.
# ajusta random forest para bases com 1 a 20 repetições de `Sepal.Length`
rfs <- map(iris3, ~ randomForest(Petal.Length ~ ., data = .x) %>% importance)
# extrai as importâncias das repetições de `Sepal.Length`
importancia <- map_dfr(rfs, ~{
.x %>%
as.data.frame() %>%
tibble::rownames_to_column() %>%
dplyr::filter(stringr::str_detect(rowname, "^Sepal.Length"))
}, .id = "n_repeticoes") %>%
mutate(n_repeticoes = as.numeric(n_repeticoes))
# Gráfico do número de variáveis multicolineares vs importância
importancia %>%
ggplot(aes(x = n_repeticoes, y = IncNodePurity)) +
geom_point() +
geom_hline(yintercept = 40, size = 1, linetype = "dashed", colour = "red") +
labs(x = "Qtd de repetições da coluna `Sepal.Length`", y = "Importância", title = "Gráfico da relação entre o número de variáveis multicolineares vs importância")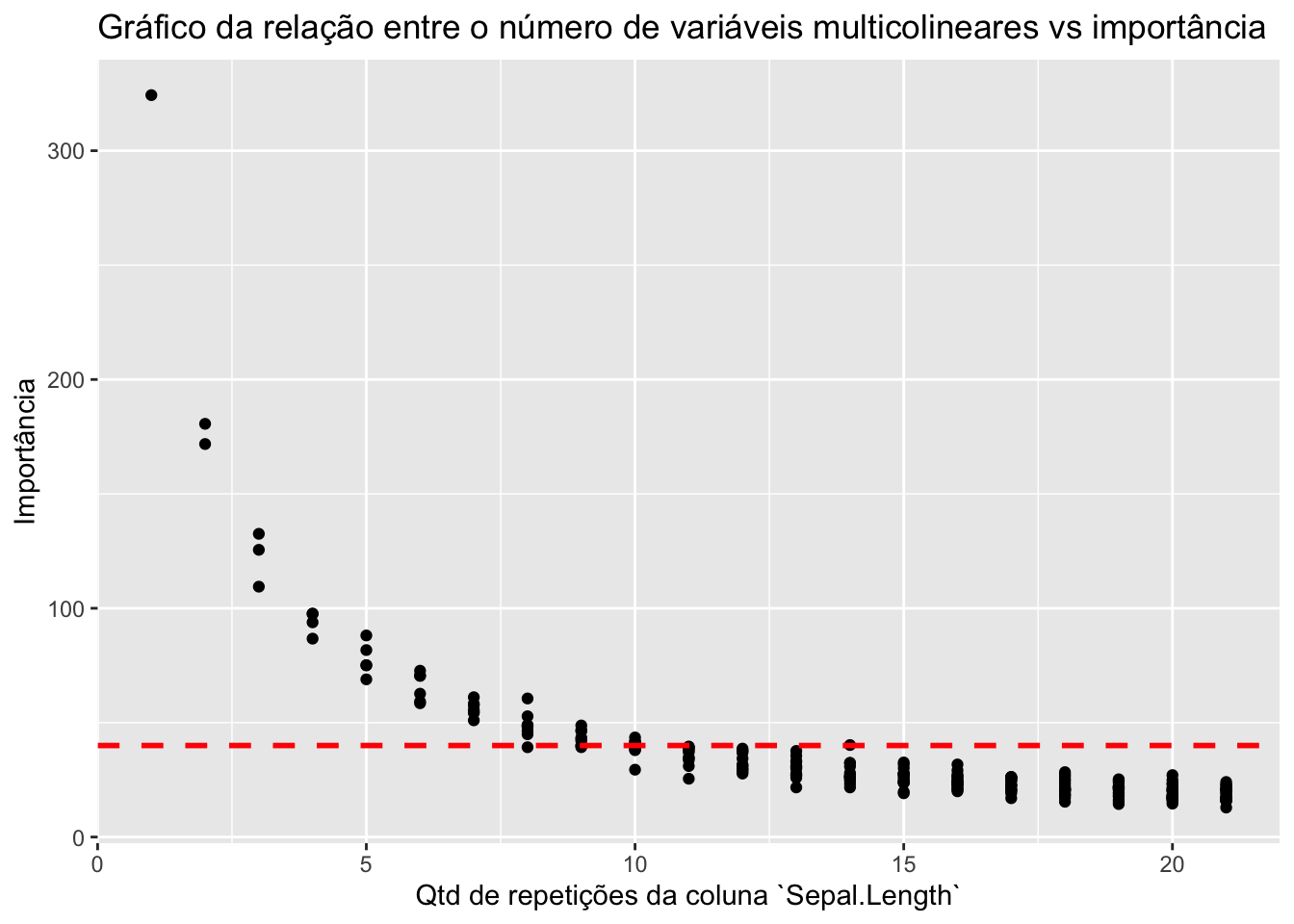
Na prática, se estabelecessemos um corte no valor de importância pra descartar variáveis (como ilustrado pela linha vermelha), teríamos um problema em potencial: poderíamos estar jogando fora informação muito importante.
Como tratar multicolinearidade, então?
Algumas maneiras de lidar com multicolinearidade são:
- Observar a matriz de correlação
- VIF
- Recursive feature elimination
Conclusão
Cuidado ao jogar tudo no caldeirão! Devemos sempre nos preocupar com multicolinearidade, mesmo ajustando modelos baseados em árvores.
Abs!


