Durante nosso último curso de introdução a programação em R, o Reinaldo Chaves me pediu ajuda para carregar os dados de CNPJs da Receita Federal. Eu me animei tanto com essa base que decidi montar um pacotinho para baixar, ler e organizar esses dados.
Pacote
O pacote rfbCNPJ baixa e lê os arquivos contendo a lista de todas as empresas do Brasil, disponibilizado pela Receita Federal em 15 de dezembro de 2017.
São duas tabelas, separadas por UF: i) empresas, contendo informações de CNPJ e nome da empresa e ii) socios, contendo quadro de sócios. Essa base de dados é atualizada pela própria RFB e eu não faço ideia de quando será atualizada novamente.
Como os arquivos são do tipo fixed width, algumas pessoas podem ter dificuldade para ler e empilhar os arquivos no R. Esse pacote facilita as operações de download e leitura.
Instalação
Você pode instalar o pacote rfbCNPJ do CRAN rodando
# ainda não foi aprovado no CRAN...
install.packages("rfbCNPJ")Você também pode baixar diretamente do GitHub rodando:
# install.packages("devtools")
devtools::install_github("jtrecenti/rfbCNPJ")Download de arquivos brutos
Você pode baixar o arquivo .txt bruto de cada UF usando o comando
rfb_download(). Por padrão, temos ufs = NULL, que baixará os arquivos
de todas as UFs. Esses arquivos somam aproximadamente 4.8 GB em disco.
rfb_download(ufs = c("AC", "RR"), path = "caminho/da/pasta")Parse
A partir de uma pasta contendo os arquivos txt, você pode carregar as bases
de dados rodando rfb_read() com os caminhos dos arquivos ou rfb_read_dir()
diretamente para ler todos os arquivos da pasta. Certifique-se de que a pasta
que contém os arquivos a serem lidos contém apenas os arquivos baixados
em .txt.
path <- "caminho/da/pasta"
all_files <- fs::dir_ls(path)
dados <- rfb_read(all_files)
dados <- rfb_read_dir(path) # equivalenteCarregando dados
Os dados são carregados numa tabela complexa com duas list-columns.
library(tibble)
print(dados, n = 27)# A tibble: 27 x 3
file empresa socio
<chr> <list> <list>
1 D71214AC.txt <tibble [15,690 × 3]> <tibble [26,268 × 6]>
2 D71214AL.txt <tibble [60,067 × 3]> <tibble [109,762 × 6]>
3 D71214AM.txt <tibble [64,306 × 3]> <tibble [121,095 × 6]>
4 D71214AP.txt <tibble [15,941 × 3]> <tibble [28,063 × 6]>
5 D71214BA.txt <tibble [422,396 × 3]> <tibble [787,637 × 6]>
6 D71214CE.txt <tibble [193,654 × 3]> <tibble [352,841 × 6]>
7 D71214DF.txt <tibble [194,734 × 3]> <tibble [368,607 × 6]>
8 D71214ES.txt <tibble [179,150 × 3]> <tibble [354,358 × 6]>
9 D71214GO.txt <tibble [328,524 × 3]> <tibble [619,810 × 6]>
10 D71214MA.txt <tibble [123,736 × 3]> <tibble [201,854 × 6]>
11 D71214MG.txt <tibble [962,930 × 3]> <tibble [1,916,405 × 6]>
12 D71214MS.txt <tibble [102,208 × 3]> <tibble [189,673 × 6]>
13 D71214MT.txt <tibble [141,464 × 3]> <tibble [262,358 × 6]>
14 D71214PA.txt <tibble [159,079 × 3]> <tibble [274,004 × 6]>
15 D71214PB.txt <tibble [79,275 × 3]> <tibble [138,596 × 6]>
16 D71214PE.txt <tibble [224,184 × 3]> <tibble [426,520 × 6]>
17 D71214PI.txt <tibble [61,627 × 3]> <tibble [105,008 × 6]>
18 D71214PR.txt <tibble [708,109 × 3]> <tibble [1,392,658 × 6]>
19 D71214RJ.txt <tibble [843,040 × 3]> <tibble [1,708,931 × 6]>
20 D71214RN.txt <tibble [80,562 × 3]> <tibble [150,411 × 6]>
21 D71214RO.txt <tibble [62,385 × 3]> <tibble [109,774 × 6]>
22 D71214RR.txt <tibble [11,908 × 3]> <tibble [21,737 × 6]>
23 D71214RS.txt <tibble [670,093 × 3]> <tibble [1,350,159 × 6]>
24 D71214SC.txt <tibble [498,511 × 3]> <tibble [974,351 × 6]>
25 D71214SE.txt <tibble [63,303 × 3]> <tibble [114,081 × 6]>
26 D71214SP.txt <tibble [2,730,412 × 3]> <tibble [5,585,988 × 6]>
27 D71214TO.txt <tibble [51,629 × 3]> <tibble [89,911 × 6]>A primeira coluna complexa mostra dados das empresas, e a segunda mostra dados dos sócios. Para carregar uma dessas listas, use tidyr::unnest(), como veremos abaixo.
Empresas:
library(magrittr)
empresas <- dados %>%
dplyr::select(file, empresa) %>%
tidyr::unnest(empresa)
empresas# A tibble: 9,048,917 x 4
file tipo cnpj nome_empresarial
<chr> <chr> <chr> <chr>
1 D71214AC.txt 01 07398403000180 BOI GORDO AGROPECUARIA COMERCIO E R…
2 D71214AC.txt 01 03173169000131 CONSELHO ESCOLAR BOM JESUS
3 D71214AC.txt 01 07399184000153 D & A SOLUCOES INFORMATICA LTDA - ME
4 D71214AC.txt 01 07399188000131 SOCIEDADE AGRICOLA POERINHA
5 D71214AC.txt 01 03300047000169 ASSOCIACAO MAO AMIGA DE PRODUTORES …
6 D71214AC.txt 01 04940648000107 ASSOCIACAO DOS PRODUTORES RURAIS E …
7 D71214AC.txt 01 04940653000101 CONSELHO ESCOLAR POLO HORTIGRANJEIRO
8 D71214AC.txt 01 04940654000156 CONSELHO ESCOLAR CENTRO EDUCACIONAL…
9 D71214AC.txt 01 03301098000105 ASSOCIACAO AGROEXTRATIVISTA SANTOS …
10 D71214AC.txt 01 01653480000152 DENEVS - TERCEIRIZACAO LTDA
# ... with 9,048,907 more rows
Sócios:
socios <- dados %>%
dplyr::select(file, socio) %>%
tidyr::unnest(socio)
socios# A tibble: 17,780,860 x 7
file tipo cnpj indicador_cpf_c… cpf_cnpj_socio qualificacao nome
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 D7121… 02 0739… 2 NA 49 SELMA…
2 D7121… 02 0739… 2 NA 22 MARCE…
3 D7121… 02 0317… 2 NA 16 MARIA…
4 D7121… 02 0739… 2 NA 49 DILSO…
5 D7121… 02 0739… 2 NA 22 ANGEL…
6 D7121… 02 0739… 2 NA 16 RAIMU…
7 D7121… 02 0330… 2 NA 16 MOISE…
8 D7121… 02 0494… 2 NA 16 RAIMU…
9 D7121… 02 0494… 2 NA 16 MARIA…
10 D7121… 02 0494… 2 NA 16 EUCLI…
# ... with 17,780,850 more rows
A descrição das qualificações pode ser encontrada na base qualificacao, disponível dentro do pacote:
data(qualificacao, package = "rfbCNPJ")
qualificacao# A tibble: 40 x 2
qualificacao qualificacao_nm
<chr> <chr>
1 05 Administrador
2 08 Conselheiro de Administração
3 10 Diretor
4 16 Presidente
5 17 Procurador
6 20 Sociedade Consorciada
7 21 Sociedade Filiada
8 22 Sócio
9 23 Sócio Capitalista
10 24 Sócio Comanditado
# ... with 30 more rowsPara juntar com a base de dados dos sócios, basta dar dplyr::inner_join()!
Download de arquivos binários
Você pode carregar os arquivos binários (em .rds) diretamente da web usando a função rfb_import(). Essa função baixa os arquivos binários diretamente do
Dropbox. Você pode baixar usando o parâmetro type=, com as opções “all”
(tibble complexa com list-columns), “empresas” (tibble retangular) e
“socios” (tibble retangular).
empresas <- rfb_import("empresas", path = ".")Você também pode baixar os dados dos arquivos binários em .rds desses links
com arquivos armazenados diretamente no dropbox:
Para ler um desses arquivos, basta rodar
dados <- readRDS("caminho/para/dados.rds")Análises
Vamos brincar um pouco com esses dados?
Empresas por UF
Minha hipótese inicial era que o estado com maior quantidade de CNPJs por pessoa era SP. Mas isso não é verdade! Os estados do Sul estão dominando, junto com DF. São Paulo aparece apenas na quarta posição.
# você pode baixar o `abjData` do GitHub rodando
# devtools::install_github("abjur/abjData")
# relação de códigos de UF e UFs
cods <- abjData::cadmun %>%
dplyr::select(uf_sigla = uf, uf_cod = UFCOD) %>%
dplyr::distinct()
# População de cada UF
pop <- abjData::pnud_uf %>%
dplyr::filter(ano == 2010) %>%
dplyr::inner_join(cods, c("uf" = "uf_cod")) %>%
dplyr::select(uf_sigla, popt)
# fazendo o join das bases!
empresas %>%
dplyr::mutate(uf_sigla = stringr::str_extract(
file, "([A-Z]{2})(?=\\.txt)")) %>%
dplyr::inner_join(pop, "uf_sigla") %>%
# calculando a razão entre população e quantidade de empresas
dplyr::group_by(uf_sigla) %>%
dplyr::summarise(n = n(),
pop = dplyr::first(popt),
prop = n / pop) %>%
dplyr::arrange(dplyr::desc(prop)) %>%
dplyr::mutate(prop = scales::percent(prop)) %>%
knitr::kable()
| UF | Qtd. Empresas | População | Razão(%) |
|---|---|---|---|
| SC | 498511 | 6199948 | 8.04% |
| DF | 194734 | 2541714 | 7.66% |
| PR | 708109 | 10348243 | 6.84% |
| SP | 2730412 | 40915382 | 6.67% |
| RS | 670093 | 10593366 | 6.33% |
| GO | 328524 | 5934767 | 5.54% |
| RJ | 843040 | 15871448 | 5.31% |
| ES | 179150 | 3477472 | 5.15% |
| MG | 962930 | 19383604 | 4.97% |
| MT | 141464 | 2961977 | 4.78% |
| MS | 102208 | 2404628 | 4.25% |
| RO | 62385 | 1515025 | 4.12% |
| TO | 51629 | 1349770 | 3.83% |
| SE | 63303 | 2038459 | 3.11% |
| BA | 422396 | 13755200 | 3.07% |
| RR | 11908 | 421159 | 2.83% |
| PE | 224184 | 8646409 | 2.59% |
| RN | 80562 | 3127820 | 2.58% |
| AP | 15941 | 652768 | 2.44% |
| CE | 193654 | 8317604 | 2.33% |
| AC | 15690 | 690774 | 2.27% |
| PA | 159079 | 7247979 | 2.19% |
| PB | 79275 | 3706991 | 2.14% |
| PI | 61627 | 3050838 | 2.02% |
| AL | 60067 | 3045851 | 1.97% |
| MA | 123736 | 6317987 | 1.96% |
| AM | 64306 | 3301221 | 1.95% |
Quantidade de sócios
Qual a distribuição de quantidade de sócios?
Para responder à essa pergunta, considerei apenas sócios pessoa física. Não fiz filtros de qualificação. Você tem alguma ideia de como poderíamos selecionar as qualificações corretas sobre a base de qualificacao?
| Qtd. Sócios | Empresas | Proporção |
|---|---|---|
| 2 | 5911971 | 65.4% |
| 1 | 2265100 | 25.0% |
| 3 | 551072 | 6.1% |
| 4 | 174558 | 1.9% |
| [5, 15] | 134898 | 1.5% |
| [16, 584] | 5714 | 0.1% |
Dois terços das empresas são formadas por dois sócios e 90% das empresas são formadas por um ou dois sócios.
Fiquei interessado em saber quais empresas estão na última faixa de quantidade de sócios. A tabela abaixo mostra as 10 empresas com mais sócios nessa base. Além da EY, não conheço nenhuma das empresas abaixo. O que dá para notar é que boa parte delas está ligada ao ramo médico.
| nome_empresarial | n |
|---|---|
| COMED - CORPO MEDICO LTDA | 584 |
| QUIRON PRONTO SOCORRO LTDA - ME | 481 |
| SIMEA - SOCIEDADE INTEGRADA MEDICA DO AMAZONAS LTDA | 391 |
| NOVA FAMILIA LTDA - EPP | 371 |
| SOCIEDADE BAURUENSE DE PRESTACAO DE SERVICOS MEDICOS SOBAME | 347 |
| ERNST & YOUNG ASSESSORIA EMPRESARIAL LTDA | 332 |
| UNIAO CONSULTORIA LTDA | 285 |
| INSTITUTO MEDICO DE CLINICA E PEDIATRIA DO ESTADO DO AMAZONAS S/S LTDA | 284 |
| UROLOGISTAS DO ESTADO DO RIO DE JANEIRO LTDA | 281 |
| SNC & CIA ADMINISTRACAO DE BENS | 277 |
Pessoas com mais empresas
Quem são os sócios com maior número de empresas? Temos abaixo uma lista dos 20 mais. Claramente, muitos desses nomes são homônimos. O primeiro nome da lista que me parece pouco provável de ter homônimos é o Renato Gamba Rocha Diniz. Também fiquei interessado nesse “Não Consta na Base”…
| nome | n_empresas |
|---|---|
| JOSE CARLOS DA SILVA | 2084 |
| JOAO BATISTA DA SILVA | 1518 |
| LUIZ CARLOS DA SILVA | 1488 |
| MARIA APARECIDA DA SILVA | 1487 |
| ANTONIO CARLOS DA SILVA | 1372 |
| JOSE CARLOS DOS SANTOS | 1339 |
| MARIA JOSE DA SILVA | 1119 |
| CARLOS ALBERTO DA SILVA | 1091 |
| JOSE CARLOS DE OLIVEIRA | 1055 |
| MARCOS ANTONIO DA SILVA | 1038 |
| NAO CONSTA NA BASE | 1035 |
| JOSE ANTONIO DA SILVA | 1017 |
| RENATO GAMBA ROCHA DINIZ | 946 |
| JOSE ROBERTO DA SILVA | 907 |
| LUIZ CARLOS DOS SANTOS | 882 |
| PAULO ROBERTO DA SILVA | 839 |
| JOSE PEREIRA DA SILVA | 804 |
| JOAO BATISTA DE OLIVEIRA | 770 |
| RENATA ROSSI CUPPOLONI RODRIGUES | 766 |
| ANTONIO CARLOS DOS SANTOS | 762 |
Sexo dos sócios
Agora vamos usar o pacote genderBR para pegar o sexo mais provável de todas as pessoas. No total, temos 11.388.120 nomes únicos na base (isso subestima a quantidade de pessoas, por conta de homônimos).
Para essa análise, tivemos de retirar 392.533 nomes em que o genderBR não foi capaz de estimar o sexo. Isso corresponde a 2,2% da base. Creio que não seja absurdo afirmar que os valores omitidos influenciam no resultado.
Nessa análise também não desconsiderei pessoas que fazem parte de mais de uma empresa. Ou seja, se uma pessoa tem 2 ou mais empresas, ela é contada 2 ou mais vezes.
Minha hipótese inicial era a de que teríamos mais homens como sócios de empresas, por razões históricas/culturais (e queremos mudar isso!). Aparentemente a hipótese foi confirmada: 3/5 dos sócios são homens. Sugiro refinar essa análise pela qualificação e pela repetição de pessoas em empresas distintas.
sexo_socios <- socios %>%
# apenas pessoas físicas
dplyr::filter(indicador_cpf_cnpj == "2") %>%
# extrai primeiro nome
dplyr::mutate(primeiro_nome = stringr::str_extract(nome, "[^ ]+")) %>%
# conta primeiro nome
dplyr::count(primeiro_nome) %>%
# estima a probabilidade de ser do sexo feminino
dplyr::mutate(sexo = genderBR::get_gender(primeiro_nome, prob = TRUE)) %>%
# retira estimações NA (cuidado!)
dplyr::filter(!is.na(sexo))library(ggplot2)
grafico <- sexo_socios %>%
# É feminino se sexo > 0.5 (mais de 50% feminino observado no IBGE)
dplyr::mutate(sexo = dplyr::if_else(sexo > .5, "Fem", "Masc")) %>%
dplyr::group_by(sexo) %>%
dplyr::summarise(total = sum(n)) %>%
dplyr::arrange(dplyr::desc(total)) %>%
# adiciona proporção em %
dplyr::mutate(prop = scales::percent(total / sum(total))) %>%
# aqui começa o gráfico
ggplot(aes(x = sexo, y = total/1000, fill = sexo)) +
geom_col() +
# daqui pra baixo é só estética
coord_flip() +
geom_text(aes(label = prop), size = 6, hjust = 1, vjust = -1) +
theme_minimal(16) +
ggtitle("Quantidade de empresas por sexo") +
labs(x = "Sexo", y = "Total (milhares)")
grafico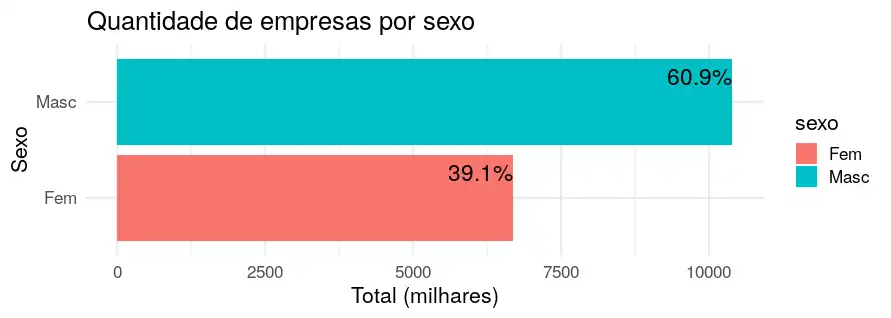
Análise Extra
O Sillas sugeriu (e executou!) uma análise adicional. A ideia era montar um grafo das empresas que compartilham sócios da Comissão de Valores Mobiliários (CVM). A CVM guarda informações de todas as empresas de capital aberto do Brasil. Uma investigação interessante é estudar se os sócios fazem parte de várias empresas. A visualização adequada para isso é um grafo das companhias, ligados pela presença de sócios com o mesmo nome.
Baixando dados da CVM
É bem tranquilo baixar as informações das empresas cadastradas na CVM:
# download do arquivo \ipado
link <- "http://sistemas.cvm.gov.br/cadastro/SPW_CIA_ABERTA.ZIP"
file_name <- "~/Downloads/companhias.zip"
httr::GET(link, httr::write_disk(file_name))
# dezipando arquivo
unzip("companhias.zip", exdir = ".")
cvm <- readr::read_delim(
file = "SPW_CIA_ABERTA.txt",
delim = "\t",
col_types = stringr::str_dup("c", 42),
locale = readr::locale(encoding = "latin1")
) %>%
# limpa os nomes zoados
janitor::clean_names()
# pega apenas empresas da CVM
socios_cvm <- socios %>%
dplyr::inner_join(cvm, "cnpj") %>%
dplyr::filter(indicador_cpf_cnpj == "2") %>%
dplyr::distinct(cnpj, nome, .keep_all = TRUE)Montando o grafo
Cada nó de nosso grafo é uma empresa Uma aresta existe entre dois nós se as empresas têm pelo menos uma pessoa em comum no quadro de sócios. Para fazer o grafo, eu fiz uma pequena alteração no código que o Sillas me mandou, para usar o visNetwork (que é dinâmico) no lugar do ggraph (que é lindo, porém estático).
# pequena limpeza na base
empresas <- socios_cvm %>%
dplyr::select(empresa = denom_comerc, pessoa = nome) %>%
dplyr::mutate(empresa = abjutils::rm_accent(empresa)) %>%
dplyr::distinct(empresa, pessoa)
# arestas do grafo
edges <- dplyr::inner_join(empresas, empresas, by = "pessoa") %>%
dplyr::filter(empresa.x != empresa.y) %>%
dplyr::distinct(empresa.x, empresa.y) %>%
dplyr::rowwise() %>%
# concatena as empresas de forma ordenada
dplyr::mutate(concat = paste(sort(c(empresa.x, empresa.y)),
collapse = "_")) %>%
dplyr::ungroup() %>%
# tira arestas duplicadas
dplyr::distinct(concat, .keep_all = TRUE) %>%
dplyr::select(from = empresa.x, to = empresa.y)
# nós do grafo
nodes <- empresas %>%
dplyr::distinct(empresa, .keep_all = TRUE) %>%
dplyr::transmute(id = empresa, label = empresa) %>%
# apenas empresas com alguma conexão
dplyr::filter(label %in% c(edges$from, edges$to))
# guarda numa lista
g <- list(nodes = nodes, edges = edges)library(visNetwork)
v <- visNetwork::visNetwork(g$nodes, g$edges)
v <- visNetwork::visOptions(v, highlightNearest = TRUE,
nodesIdSelection = TRUE)
vUse seu mouse para navegar no grafo e descobrir os principais clusters de empresas!
Wrap-up
- O pacote
rfbCNPJserve para organizar os dados de CNPJ da Receita Federal. - Use a função
rfb_import()para ler os binários prontinhos para leitura diretamente do dropbox. - Além de descobrir todos os 9.048.917 CNPJs e 11.388.120 nomes únicos de pessoas, podemos fazer análises exploratórias com esses dados.
Links e agradecimentos
- Valeu, amigos da curso-r.com e agregados, que me orientaram a criar a função
rfb_import(). - Veja também o Brasil.io do Turicas, que tem os mesmos arquivos para download. Ele me informou também que a base dele é mais confiável, pois apresenta correções de dados incorretos da Receita.
- Acompanhe o blog do Sillas que é muito mara!
É isso. Happy coding ;)


