Olá! Tudo bem? Eu sou a Bruna,
e talvez você já me conheça de algum grupo de R no Telegram
ou Facebook, ou mesmo pelo meu outro pacote, o
vagalumeR. Eu estou prestes a me formar em Estatística na
UFPR, e esse post vai ter muito a ver com o tema do meu
trabalho de conclusão de curso, que está sendo feito
sob orientação do Professor
Walmes Zeviani.
Recentemente, eu fiz a primeira versão do pacote do meu TCC,
o chorrrds. Ainda tem muito a ser feito nele, mas os primeiros
resultados já são bem legais. O pacote chorrrds pode ser
utilizado para a obtenção acordes de músicas, através da
raspagem do site CifraClub.
Junto com o pacote já vêm diversos bancos de dados
relativos à música brasileira. Ele já está disponível no
CRAN, mas as próximas atualizações devem sair em
primeira mão nesse repositório: https://github.com/brunaw/chorrrds
# Instalação
devtools::install_github("brunaw/chorrrds")
# ou
install.packages("chorrrds") # do CRAN
data(package = "chorrrds")A base de dados chamada all, presente no pacote, contém dados
referentes a 106 artistas nacionais, dos genêros: “rock”, “pop”,
“sertanejo”, “MPB”, “bossa nova”, “forró”, “reggae” e “samba”.
Ela já contém, além das variáveis extraídas com o pacote,
as datas de lançamento e a popularidade das músicas, obtidas
através da API do
Spotify. Os
detalhes sobre a seleção dos artistas e combinação dos
dados com os do Spotify serão omitidos por enquanto, mas
quem quiser falar sobre isso comigo, pode ficar a vontade :)
Então vamos lá. Eu vou começar acertando alguns pontos sobre os dados, já que eles não estão perfeitos, como:
- Deixar apenas os anos de lançamento das músicas, e não a data completa;
- Encontrar as formas mais simples dos acordes (sem acidentes ou extensões);
- Conectar a base original com a dos genêros dos artistas;
- Consertar enarmonias, ou seja, transformar as diferentes versões de um acorde com as mesmas notas em uma coisa só (por exemplo, Gb passa a ser F#, já que na prática eles são iguais).
library(tidyverse)
# Base de gêneros
genre <- chorrrds::genre
da <- chorrrds::all %>%
dplyr::mutate(date = stringr::str_extract(date,
pattern = "[0-9]{4,}")) %>%
# Extrai apenas os anos
dplyr::mutate(date = as.numeric(date), # Deixa as datas como valores numéricos
acorde = stringr::str_extract(chord, # Extrai as partes fundamentais dos
pattern = "^([A-G]#?b?)")) %>% # acordes
dplyr::filter(date > 1900) %>% # Mantém apenas os anos que fazem sentido
dplyr::left_join(genre, by = "artist") %>% # Traz os gêneros dos artistas
dplyr::mutate(acorde = case_when( # Contribuição do Julio
acorde == "Gb" ~ "F#",
acorde == "C#" ~ "Db",
acorde == "G#" ~ "Ab",
acorde == "A#" ~ "Bb",
acorde == "D#" ~ "Eb",
acorde == "E#" ~ "F",
acorde == "B#" ~ "C",
TRUE ~ acorde)) # Conversão de enarmonias
head(da)| date | music | popul | chord | key | artist | acorde | genre |
|---|---|---|---|---|---|---|---|
| 1992 | adriana calcanhotto a fabrica do poema | 51 | Cm | D# | adriana calcanhotto | C | MPB |
| 1992 | adriana calcanhotto a fabrica do poema | 51 | Ab | D# | adriana calcanhotto | Ab | MPB |
| 1992 | adriana calcanhotto a fabrica do poema | 51 | Db7 | D# | adriana calcanhotto | Db | MPB |
| 1992 | adriana calcanhotto a fabrica do poema | 51 | Db7/9 | D# | adriana calcanhotto | Db | MPB |
| 1992 | adriana calcanhotto a fabrica do poema | 51 | Cm | D# | adriana calcanhotto | C | MPB |
| 1992 | adriana calcanhotto a fabrica do poema | 51 | Fm | D# | adriana calcanhotto | F | MPB |
A base está no formato longo, ou seja, temos uma linha para cada acorde da música, mantendo a sequência na qual eles aparecem no site.
Muito se fala sobre o quanto as músicas no Brasil andam ficando mais “simples”, ou que alguns genêros musicais são mais ricos que outros. Com os dados que temos, será que é possível concluir algo sobre isso olhando simplesmente para a quantidade média de acordes por música ao longo dos anos? Vejamos o gráfico a seguir.
da_g <- da %>%
# 2018 ainda não é um ano completo
dplyr::mutate(date < 2018) %>%
# Agrupamento por data + acorde + musica
dplyr::group_by(date, genre, music, chord) %>%
# Mantém os acordes distintos/ano
dplyr::summarise(distintos = n_distinct(chord)) %>%
dplyr::summarise(cont = n()) %>%
# Média de acordes distintos nas músicas/ano
dplyr::summarise(media = mean(cont), contagem = n())
# grafico
p <- da_g %>%
ggplot(aes(x = date, y = media)) +
geom_point(colour = "skyblue3") +
facet_wrap("genre") +
scale_fill_hue(c = 55, l = 75) +
geom_smooth(aes(group = genre), span = 0.65, colour = "white",
fill = "tan", method = "loess") +
labs(x = "Anos", y = "Média de acordes/música")
# tema para deixar o gráfico bonitinho
tema <- theme(
legend.position='none',
axis.line = element_line(size = 0.5, colour = "tan"),
panel.grid.major = element_line(
colour = "black", size = 0.08, linetype = "dotted"),
panel.border = element_blank(),
panel.background = element_blank(),
strip.background = element_rect(colour = "tan", fill = "white", size = 0.6),
strip.text = element_text(size = 14),
axis.title = element_text(size = 14),
axis.text = element_text(size = 12))
p + tema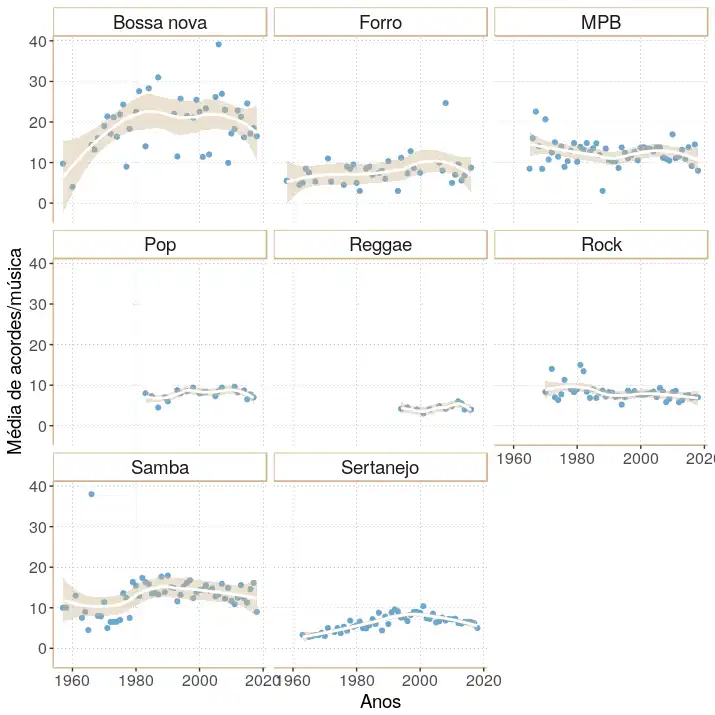
Claramente, gêneros como o samba, MPB e bossa nova têm, em geral, uma quantidade média de acordes distintos por música muito maior do que os outros. E eles têm mais variação ao longo dos anos também, o que pode ser um reflexo da maior criatividade envolvida nestes genêros. Os menores valores, como é esperado, estão principalmente no sertanejo, que é um genêro conhecidamente mais uniforme na questão harmônica.
Nós podemos avançar um pouco e olhar para os próprios artistas. Quem será que usa as maiores quantidades de acordes distintos em suas composições? Vamos ver o próximo gráfico, que mostra apenas os artistas com mediana maior do que 8 acordes diferentes por música.
da_g <- da %>%
dplyr::mutate(artist = stringr::str_to_title(artist)) %>%
# Agrupamento por artista + música
dplyr::group_by(artist, genre, music) %>%
# Mantém os acordes distintos
dplyr::summarise(distintos = n_distinct(chord)) %>%
# Obtém a mediana e quantis de acordes distintos por música/artistas
dplyr::summarise(med = median(distintos),
contagem = n(),
inf = quantile(distintos)[2],
sup = quantile(distintos)[4])
# grafico
p <- da_g %>%
dplyr::filter(med > 8) %>%
ggplot(aes(x = reorder(artist, med), y = med)) +
geom_pointrange(aes(ymin = inf, ymax = sup, colour = genre), size = 0.7) +
scale_colour_hue(c = 55, l = 75) +
coord_flip() +
labs(colour = "Gênero",
x = "Artistas",
y = "Primeiro quartil, mediana e terceiro quartil")
# tema
tema <- theme(
axis.line = element_line(size = 0.5,
colour = "tan"),
panel.grid.major = element_line(colour = "black",
size = 0.08,
linetype = "dotted"),
panel.border = element_blank(),
panel.background = element_blank(),
axis.text = element_text(size = 12),
axis.title.x = element_text(size = 16),
axis.title.y = element_text(size = 16))
p + tema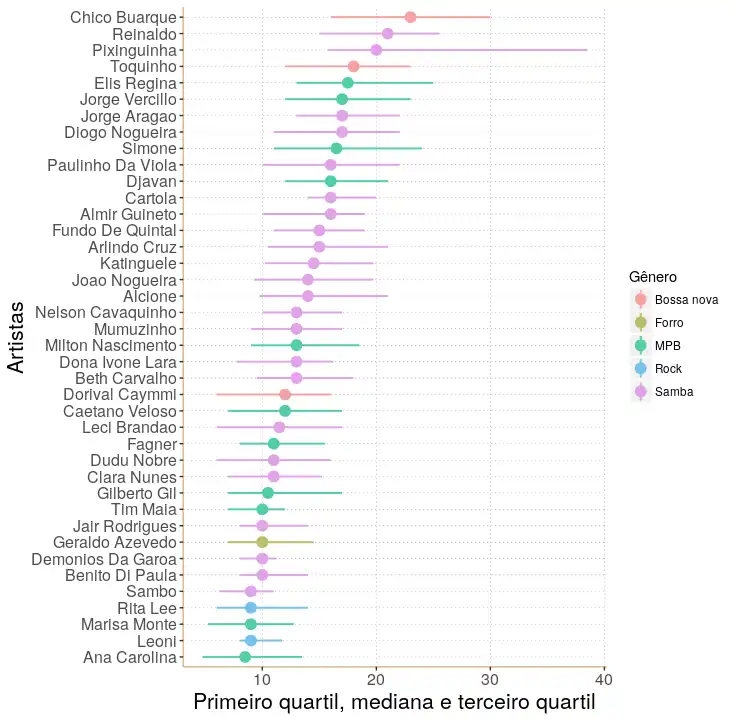
E voilá. A primeira posição é ocupada por um dos maiores musicistas brasileiros, que é referência internacional em questões de harmonia: Chico Buarque. Logo em seguida, temos o Reinaldo, um dos maiores sambistas que o Brasil já conheceu, e o Pixinguinha, um gênio do choro. E assim a lista segue, com artistas principalmente da bossa nova, samba e MPB. Demora até que apareça o primeiro dos rockeiros nesta lista, que é a Rita Lee. Dos membros do sertanejo, nenhum chega a aparecer no gráfico, mostrando que a “variedade” harmônica deste gênero musical é mesmo bem baixa.
Até agora está legal mas, com música, sempre pode ficar ainda mais. A ideia mais recente que o meu caro orientador Walmes Zeviani teve para o nosso trabalho é de encadear as transições entre os acordes em um diagrama de cordas. Vocês já ouviram falar desse diagrama? Eu mal o conheço e já considero pacas.
O diagrama de cordas é um método gráfico (e lindo) de explicitar relações entre grupos ou indivíduos. Os grupos ficam arranjados de forma radial/circular, e as cordas que aparecem dentro do círculo demonstram as conexões entre eles e suas forças. Pra quem sabe um pouquinho sobre harmonia, vai ser sensacional ver o quanto isso faz sentido (mas também não vou entrar nesse mérito agora).
O exemplo que eu vou mostrar aqui é extremamente simples. Antes eu separei, dos acordes “crus” retirados do CifraClub, apenas a parte fundamental deles. Isto é, desconsiderei se um acorde tem notas extras, acidentes e maior/menor. Ou seja, aqui nós só veremos acordes como C, D, B, A#, o miolo da coisa. Podemos perder informação fazendo isso? Sim, e bastante. Mas como eu disse, esse caso é pra ser bem simples mesmo.
Enfim, vamos voltar ao exemplo. A seguir, eu considero como
uma “transição” quando um acorde aparece em sequência do outro
(exemplo de transição muito comum: dó-sol). O código abaixo
constrói o diagrama de cordas através do pacote chordiag:
devtools::install_github("mattflor/chorddiag")# Ordenando por círculo das quintas
ordem <- c("G", "D", "A", "E", "B", "F#",
"Db", "Ab", "Eb", "Bb", "F", "C")
da$acorde <- factor(da$acorde, levels = ordem)
comp <- data.frame(
acorde = da$acorde,
seq = dplyr::lead(da$acorde)) %>% # Pega o acorde "seguinte"
dplyr::group_by(acorde, seq) %>% # Agrupa por cada transição
dplyr::summarise(contagem = n()) # Conta quantas são as transições
mat_comp <- reshape2::dcast(comp, # Arranja em do tipo matriz quadrada
acorde ~ seq, value.var = "contagem")
mm <- as.matrix(mat_comp[ ,-1]) # Converte o df em matriz (exigência do pacote)
mm[is.na(mm)] <- 0 # Substitui na por 0 (exigência do pacote)
dimnames(mm) <- list(acorde = unique(mat_comp$acorde),
seq = unique(mat_comp$acorde))
# Constrói o diagrama interativo
chorddiag::chorddiag(mm, showTicks = FALSE,
palette = "Set2", palette2 = "#Set3")Vejam que interessante. Como eu disse antes, uma das relações mais fortes do diagrama é o C-G (ou dó-sol), que é justificada teoricamente, já que o G é a quinta do C. O mesmo acontece com D-A, A-E, F-C e assim por diante. Quem quiser saber mais sobre esse comportamento, pode dar uma olhada aqui. Transições meio malucas, como B-Bb, também acontecem. “Maluca” porque um acorde bemol, indicado pelo “b”, é aquele cuja raíz esta meio tom abaixo do indicado pela letra anterior, que neste caso é o B (si), então esse acontecimento não faz muito sentido.
Considerações Finais
O que vimos aqui é um pedaço da análise inicial do meu TCC,
que ainda não está nem um pouco pronto. São exemplos
simples das informações podemos extrair com o pacote chorrrds,
e o universo de possibilidades é infinito. Isso que nós nem
começamos a falar sobre as conexões que podem ser feitas
com a API do Spotify, o pacote music21, que é do próprio
Julio Trecenti, com as letras das músicas,…
Além disso, om certeza, meu objetivo com os gráficos apresentados não é fazer nenhum tipo de juízo de valor sobre os genêros por conta de “complexidade harmônica”. Diga-se de passagem, eu mesma sou bem fã de todos esses genêros, desde a MPB até o sertanejo :D
Agradecimentos
Ao meu orientador, Walmes Zeviani, que fez eu me apaixonar pelo R, e ao Julio Trecenti, que é tão entusiasta do meu TCC quanto eu, e já fez diversas contribuições valiosas.


