Tiago Belotti é o meu crítico de cinema favorito. Gasto uma quantidade de tempo que não me orgulho vendo os vídeos desse ser maravilhoso. Atualmente, muitas vezes eu prefiro ver a crítica dele do filme que o próprio filme, seguindo cegamente as indicações dele a partir das notas que ele coloca no final da crítica. Recomendo fortemente que acessem o canal do Belotti.

O Tiago já mencionou várias vezes que as notas que ele dá aos filmes não representam toda a crítica realizada. Por exemplo, ele já montou listas de Top 10 colocando filmes com notas medianas à frente de filmes com notas altas. Mesmo assim, não dá pra não querer saber a nota que ele dá aos filmes, é um vício!
A minha necessidade visceral de saber as notas dadas aos filmes começou quando a seguinte pergunta apareceu na minha mente:
Será que o Tiago está ficando bonzinho? A nota média está aumentando ao longo do tempo?
E assim acabou o meu final de semana. Eu precisava obter esses dados de qualquer forma.
Como extrair as notas dos vídeos
O código para extrair as notas é pra lá de esotérico e usa um monte de funções auxiliares de pacotes do linux. Como o amigo Caio Lente adora falar, meus códigos costumam ter muitas partes móveis…
A obtenção das notas dos filmes passa pelo seguinte fluxo:
- Baixar os vídeos do youtube
- Extrair os frames dos vídeos
- Encontrar a imagem que tem a nota
- Limpar a imagem que tem a nota
- Passar um algoritmo de OCR (Optical Character Recognition) na imagem
- Cruzar com uma base de metadados do YouTube, usando o pacote
tuber
Vou explicar brevemente como cada um desses passos foi executado. O código não é totalmente reprodutível pois o código completo com os loops ficaria pouco legível.
Passo 1: Baixar os vídeos
Os vídeos foram baixados usando um pacote chamado youtube-dl. Para instalá-lo num Ubuntu 16.04 podemos rodar
sudo apt install youtube-dlO download da lista de reprodução do Tiago Belotti de 2015 pode ser realizada rodando, por exemplo:
youtube-dl -f 160 https://www.youtube.com/playlist?list=PLy-phHpv7EKaioTZ39lNd_nvitGNtQadlRealizei o download numa resolução bem ruim e sem áudio, para ocupar pouco espaço em disco. Faça isso para todos os anos (2013 até 2017) e pronto! Temos os vídeos.
Passo 2: Extrair os frames dos vídeos
Os arquivos de vídeo foram transformados utilizando ffmpeg, também baixado como pacote do linux. Para instalá-lo num Ubuntu 16.04 podemos rodar
sudo apt install ffmpegA função tirar_screenshots() recebe o nome de um arquivo de vídeo, cria uma pasta com esse nome e salva os screenshots na pasta.
tirar_screenshots <- function(vfile) {
# folder and file names
file_name <- tools::file_path_sans_ext(basename(vfile))
folder_name <- glue("imgs/{file_name}")
if (!file.exists(folder_name)) {
dir.create(folder_name, showWarnings = FALSE, recursive = TRUE)
out <- glue("{folder_name}/out_")
# take screenshots
take_shots <- glue("ffmpeg -y -i '{vfile}' -vf fps=1 '{out}%04d.png'")
system(take_shots)
}
}Basta fazer um loop (com purrr, não for, rs) para processar todos os arquivos de vídeo. Resultado:

Passo 3: Encontrar a imagem que tem a nota
A nota geralmente aparece no canto superior direito da imagem:

Então, vamos recortar esse pedaço e pegar qual imagem tem maior concentração de vermelho. A função cortar_canto() utiliza o magick para pegar o canto da imagem e salva num arquivo temporário.
cortar_canto <- function(img_file) {
img_file %>%
magick::image_read() %>%
magick::image_crop("x60+180") %>%
magick::image_write(tempfile())
}A função somar_vermelho() pega a imagem e calcula a quantidade de vermelhos, tirando os casos em que há vermelho conjuntamente com outras cores (como branco, por exemplo).
somar_vermelho <- function(img_file) {
p <- png::readPNG(img_file)
if (length(dim(png_img)) != 3) return(0)
sum(p[,,1] == 1.0 & p[,,2] < 0.1 & p[,,3] < 0.1)
}Assim, a soma de vermelhos de um arquivo fica
"out_0277.png" %>%
cortar_canto() %>%
somar_vermelho()
# [1] 758Basta rodar isso para todos os arquivos e depois selecionar a imagem que tem a maior contagem.
Passo 4: Limpar a imagem que tem a nota
A função limpar_imagem() recebe a imagem cortada e faz a limpeza, soltando apenas os números, prontos para receber o algoritmo de OCR.
limpar_imagem <- function(img_cut) {
tmp <- tempfile()
# filtros a serem aplicados em cada cor
parms <- c(red = .9, green = .2, blue = .2)
png::readPNG(img_cut) %>%
purrr::array_branch(3) %>%
purrr::map2(parms, ~.x > .y) %>%
purrr::map_at(2:3, magrittr::not) %>%
purrr::reduce(magrittr::and) %>%
magrittr::multiply_by(-1) %>%
magrittr::add(1) %>%
png::writePNG(tmp)
tmp
}"out_0277.png" %>%
cortar_canto() %>%
limpar_imagem()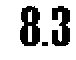
Passo 5: Passar um algoritmo de OCR
Finalmente, a função pegar_nota() utiliza tesseract para transformar as imagens em números
pegar_nota <- function(img_filtered) {
# whitelist de numeros
engine <- tesseract::tesseract(options = list(
tessedit_char_whitelist = "1234567890."))
# apply tesseract
img <- img_filtered %>%
magick::image_read() %>%
magick::image_trim() %>%
tesseract::ocr(engine = engine) %>%
readr::parse_number()
}A utilização final do algoritmo fica assim:
"out_0277.png" %>%
cortar_canto() %>%
limpar_imagem() %>%
pegar_nota()
# [1] 8.3Pronto! Agora é só loopar em todos os arquivos e teremos as notas de todos os filmes.
Infelizmente, o algoritmo de OCR do tesseract não é lá essas coisas, e precisei arrumar muitos desses dados na mão.
Passo 6: Cruzar com uma base de metadados do YouTube
Agora, vamos cruzar com os metadados do youtube. Os nomes dos arquivos baixados pelo youtube-dl vêm com um código no final, por exemplo com UVN6ljuRzp8. É possível utilizar esses códigos no tuber para obter metadados de um vídeo, dessa forma:
## código para obter um token de acesso
# tuber::yt_oauth(
# "998136489867-5t3tq1g7hbovoj46dreqd6k5kd35ctjn.apps.googleusercontent.com",
# "MbOSt6cQhhFkwETXKur-L9rN")
detalhes <- tuber::get_video_details("UVN6ljuRzp8")
## pegar nome do filme
purrr::pluck(detalhes, 4, 1, "snippet", "title")
# [1] "JOGO PERIGOSO (Gerald's Game, Netflix, 2017) - Crítica"
## pegar data de disponibilização
purrr::pluck(detalhes, 4, 1, "snippet", "publishedAt")
# [1] "2017-10-07T14:39:54.000Z"Usei esses metadados para extrair a data de disponibilização dos vídeos. No final, fiquei com a seguinte base de dados com 386 filmes classificados (mostrando apenas 20 linhas):
| id | nm | data | nota |
|---|---|---|---|
| j5udRStwytk | 007 CONTRA SPECTRE (2015) | 2015-11-05 | 6.4 |
| HdYnkiiWwe8 | 120 BATIMENTOS POR MINUTO (2017) | 2018-01-04 | 8.6 |
| GXfe2CSKiHw | 12 YEARS A SLAVE (12 Anos de Escravidão, 2013) | 2014-01-04 | 9.0 |
| j-kiltl6_uk | 1922 (Netflix, 2017) | 2017-10-24 | 7.0 |
| zsNoXCMnTmo | 300 - A ASCENSÃO DO IMPÉRIO (2014) | 2014-03-07 | 7.1 |
| 60hUNlmK30A | A AUTÓPSIA (The Autopsy of Jane Doe, 2016) | 2017-05-01 | 5.7 |
| 1sNNzBDVlLk | A BELA E A FERA (Beauty and the Beast, 2017) | 2017-03-16 | 8.5 |
| Zuk5QzVccWA | ABOUT TIME (Questão de Tempo, 2013) | 2013-11-28 | 8.1 |
| aRjxN0ShsE8 | A BRUXA (The Witch, 2016) | 2016-03-05 | 8.2 |
| n4xrIu4xKo8 | A CABANA (The Shack, 2017) | 2017-04-07 | 3.4 |
| t8W-DbCbPVY | A CHEGADA (Arrival, 2016) | 2016-11-22 | 9.4 |
| M5GBLtYgz14 | A COLINA ESCARLATE (Crimson Peak, 2015) | 2015-10-15 | 6.2 |
| Sv-M7jfTGM0 | A CULPA É DAS ESTRELAS (The Fault in Our Stars, 2014) | 2014-06-05 | 7.2 |
| EALV4nw-vx0 | A ENTREVISTA (The Interview, 2014) | 2014-12-27 | 6.7 |
| 4I44eE82Jk4 | A FORMA DA ÁGUA (The Shape of Water, 2017) | 2018-01-24 | 9.3 |
| MnpZqlfZ_KE | A GAROTA DINAMARQUESA (The Danish Girl, 2015) | 2016-02-12 | 6.8 |
| HjAxuKPzucY | A GAROTA NO TREM (The Girl on the Train, 2016) | 2016-10-27 | 5.1 |
| UuyN4G9BQgI | A GHOST STORY (2017) | 2017-09-28 | 10.0 |
| 9irKAQoDN88 | A GRANDE APOSTA (The Big Short, 2015) | 2016-01-18 | 7.8 |
| bNsUkl8hGvk | ÁGUAS RASAS (The Shallows, 2016) | 2016-08-07 | 7.0 |
Análises
Agora que temos uma base de dados, podemos fazer algumas análises!
Primeiro, é claro, vamos fazer os top 20 e os top -20
notas_2cents %>%
dplyr::select(nm, nota) %>%
dplyr::arrange(desc(nota)) %>%
utils::head(20) %>%
knitr::kable()| nm | nota |
|---|---|
| A GHOST STORY (2017) | 10.0 |
| A QUALQUER CUSTO (Hell or High Water, 2016) | 10.0 |
| BINGO - O REI DAS MANHÃS (2017) | 10.0 |
| BLADE RUNNER 2049 (2017) | 10.0 |
| ELLE (2016) | 10.0 |
| MAD MAX - ESTRADA DA FÚRIA (2015) | 10.0 |
| MOONLIGHT (2016) | 10.0 |
| RELATOS SELVAGENS (Relatos salvajes, 2014) | 10.0 |
| SPOTLIGHT (Segredos Revelados, 2015) | 10.0 |
| THE HANDMAIDEN (Ah-ga-ssi, 2016) | 10.0 |
| O QUARTO DE JACK (Room, 2015) | 9.9 |
| TRÊS ANÚNCIOS PARA UM CRIME (2017) | 9.9 |
| BOYHOOD (2014) | 9.7 |
| DEADPOOL (2016) | 9.5 |
| WHIPLASH - EM BUSCA DA PERFEIÇÃO (2014) | 9.5 |
| A CHEGADA (Arrival, 2016) | 9.4 |
| AMOR & AMIZADE (Love & Friendship, 2016) | 9.4 |
| CORRA! (Get Out, 2017) | 9.4 |
| LA LA LAND (2016) | 9.4 |
| O REGRESSO (The Revenant, 2015) | 9.4 |

Não assistiu a algum desses filmes? Tá na hora de ver!
notas_2cents %>%
dplyr::select(nm, nota) %>%
dplyr::arrange(nota) %>%
utils::head(20) %>%
knitr::kable()| nm | nota |
|---|---|
| DEUSES DO EGITO (Gods of Egypt, 2016) | 0.0 |
| PORTA DOS FUNDOS - CONTRATO VITALÍCIO (2016) | 2.1 |
| MULHERES AO ATAQUE (The Other Woman, 2014) | 2.3 |
| CINQUENTA TONS DE CINZA (2015) | 2.5 |
| TRANSFORMERS - A ERA DA EXTINÇÃO (2014) | 2.5 |
| INFERNO (2016) | 3.3 |
| A CABANA (The Shack, 2017) | 3.4 |
| ASSASSINS CREED (2016) | 3.5 |
| ALICE ATRAVÉS DO ESPELHO (2016) | 3.6 |
| FRANKENSTEIN - ENTRE ANJOS E DEMÔNIOS (2014) | 3.6 |
| PETER PAN (Pan, 2015) | 3.6 |
| A MÚMIA (The Mummy, 2017) | 3.8 |
| ANTES QUE EU VÁ (Before I Fall, 2017) | 3.8 |
| QUARTETO FANTÁSTICO (2015) | 3.8 |
| CONVERGENTE (Allegiant, 2016) | 3.9 |
| DEBI & LÓIDE 2 (Dumb and Dumber To, 2014) | 3.9 |
| JOGOS MORTAIS - JIGSAW (2017) | 4.0 |
| JUNTOS E MISTURADOS (Blended, 2014) | 4.0 |
| The Mortal Instruments - City of Bones (2013) | 4.0 |
| ANNABELLE (2014) | 4.1 |
Já assistiu a algum desses filmes? Meus pêsames!
Testando a minha hipótese
Finalmente, pude testar minha hipótese!
p <- notas_2cents %>%
ggplot(aes(x = data, y = nota, group = nm)) +
geom_point() +
geom_smooth(aes(group = 1), method = "lm", se = FALSE) +
theme_minimal(16)
plotly::ggplotly(p)
## `geom_smooth()` using formula 'y ~ x'
## Warning: `group_by_()` is deprecated as of dplyr 0.7.0.
## Please use `group_by()` instead.
## See vignette('programming') for more help
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_warnings()` to see where this warning was generated.Parece que a nota média do Tiago Belotti subiu um pouquinho ao longo dos anos, mas nada muito significativo. Ou seja, minha hipótese de que o Tiago Belotti ficou mais bonzinho não se verifica. Ele é super consistente!
Outras investigações que eu gostaria de fazer:
- Qual a relação das notas do Tiago com o Rotten Tomatoes ou o IMDb?
- Será que é possível prever a nota do Tiago com base em outras notas e características do filme?
- O Tiago avalia diferente filmes de gêneros diferentes?
Para essas investigações, seria necessário cruzar essa base com a base do Rotten Tomatoes e do IMDb. Quem sabe num próximo post!
É isso pessoal. Um abraço, e até a próxima.

Agradecimentos
Sillas pelas ideias de visualização, que acabei não postando. E também para os amigos que brincaram comigo na datathon sobre isso: Bruna Wunderwald, Luciana Keiko, William, Caio Lente, Guilherme e quem mais eu tiver esquecido.
Cursos R básico e Web Scraping
Não perca a oportunidade de se inscrever nos nossos cursos!


