Se você ainda não é adepta ou adepto do tidyverse, provavelmente precisa setar stringsAsFactors = FALSE em algum momento ou sempre trabalha com fatores em vez de strings.
Strings são sequências de caracteres que podem ser acessados pela sua posição. Assim, podemos usar expressões regulares para modificar partes da sequência que correspondam a um determinado padrão. Fatores são inteiros com categorias (ou labels) formadas por strings guardadas apenas uma vez no atributo levels. Por facilitarem a ordenação de valores de texto, eles são importantes para a criação de variáveis dummies e a definição de contrastes em funções de modelagem estatística, como a lm(), e a organização de atributos gráficos, como no pacote ggplot2.
Há motivos históricos para funções como read.table() e data.frame() fazerem, por default, a coerção de caracteres para fatores. Você pode ler sobre isso nos posts stringsAsFactors: An unauthorized biography, do Roger Peng, e stringsAsFactors =
Além de não transformar strings em fatores, o tidyverse também dispõe de um pacote só para manipular fatores: o forcats (for categorial variables). Para começar a usá-lo, instale e carregue o pacote.
install.packages("forcats")library(forcats)
library(tidyverse)O forcats é um pacote bastante simples. Basicamente, ele é composto por funções de apenas dois tipos:
- Funções que começam com
fct_, que recebem uma lista de fatores e devolvem um fator. - Funções que começam com
lvl_, que modificam os níveis de um fator.
Veja a seguir exemplos de como utilizar as principais funções.
fct_recode
Altera categorias específicas de um fator.
fator <- factor(c("Scorsese", "DiCaprio", "Patty Jenkins", "Gal Gadot"))
# Alterando apenas uma
fct_recode(fator, direcao = "Scorsese")
## [1] direcao DiCaprio Patty Jenkins Gal Gadot
## Levels: DiCaprio Gal Gadot Patty Jenkins direcao
# Alterando todas
fct_recode(fator,
direcao = "Scorsese",
direcao = "Patty Jenkins",
elenco = "DiCaprio",
elenco = "Gal Gadot")
## [1] direcao elenco direcao elenco
## Levels: elenco direcaofct_collapse
Junta categorias em grupos manualmente definidos.
# Objeto simulando uma amostra do personagem
# de série favorito de 100 pessoas
nomes <- c("Sheldon", "Leonard", "Penny", "Howard", "Rajesh",
"Ted", "Marshall", "Robin", "Lily", "Barney",
"Michael", "Jim", "Pam", "Dwight", "Andy")
per_fav<- sample(x = nomes, size = 100, replace = T) %>%
as.factor
head(per_fav)
## [1] Sheldon Robin Lily Sheldon Jim Pam
## 15 Levels: Andy Barney Dwight Howard Jim Leonard Lily Marshall Michael ... Ted
# Conta o número de observações em cada categoria
fct_count(per_fav)
## # A tibble: 15 × 2
## f n
## <fct> <int>
## 1 Andy 5
## 2 Barney 11
## 3 Dwight 5
## 4 Howard 7
## 5 Jim 6
## 6 Leonard 10
## 7 Lily 5
## 8 Marshall 4
## 9 Michael 6
## 10 Pam 9
## 11 Penny 9
## 12 Rajesh 4
## 13 Robin 5
## 14 Sheldon 6
## 15 Ted 8
# Junta as categorias
per_fav2 <- fct_collapse(per_fav,
TBBT = c("Sheldon", "Leonard", "Penny", "Howard", "Rajesh"),
HIMYM = c("Ted", "Marshall", "Robin", "Lily", "Barney"),
TheOffice = c("Michael", "Jim", "Pam", "Dwight", "Andy"))
head(per_fav2)
## [1] TBBT HIMYM HIMYM TBBT TheOffice TheOffice
## Levels: TheOffice HIMYM TBBT
fct_count(per_fav2)
## # A tibble: 3 × 2
## f n
## <fct> <int>
## 1 TheOffice 31
## 2 HIMYM 33
## 3 TBBT 36fct_reorder
Ordena as categorias de um fator segundo uma função. No exemplo abaixo, ordenamos os fatores da variável carb (número de carburadores) segundo a mediana da variável mpg (milhas por galão de combustível).
mtcars %>%
ggplot(aes(x = as.factor(carb), y = mpg)) +
geom_boxplot()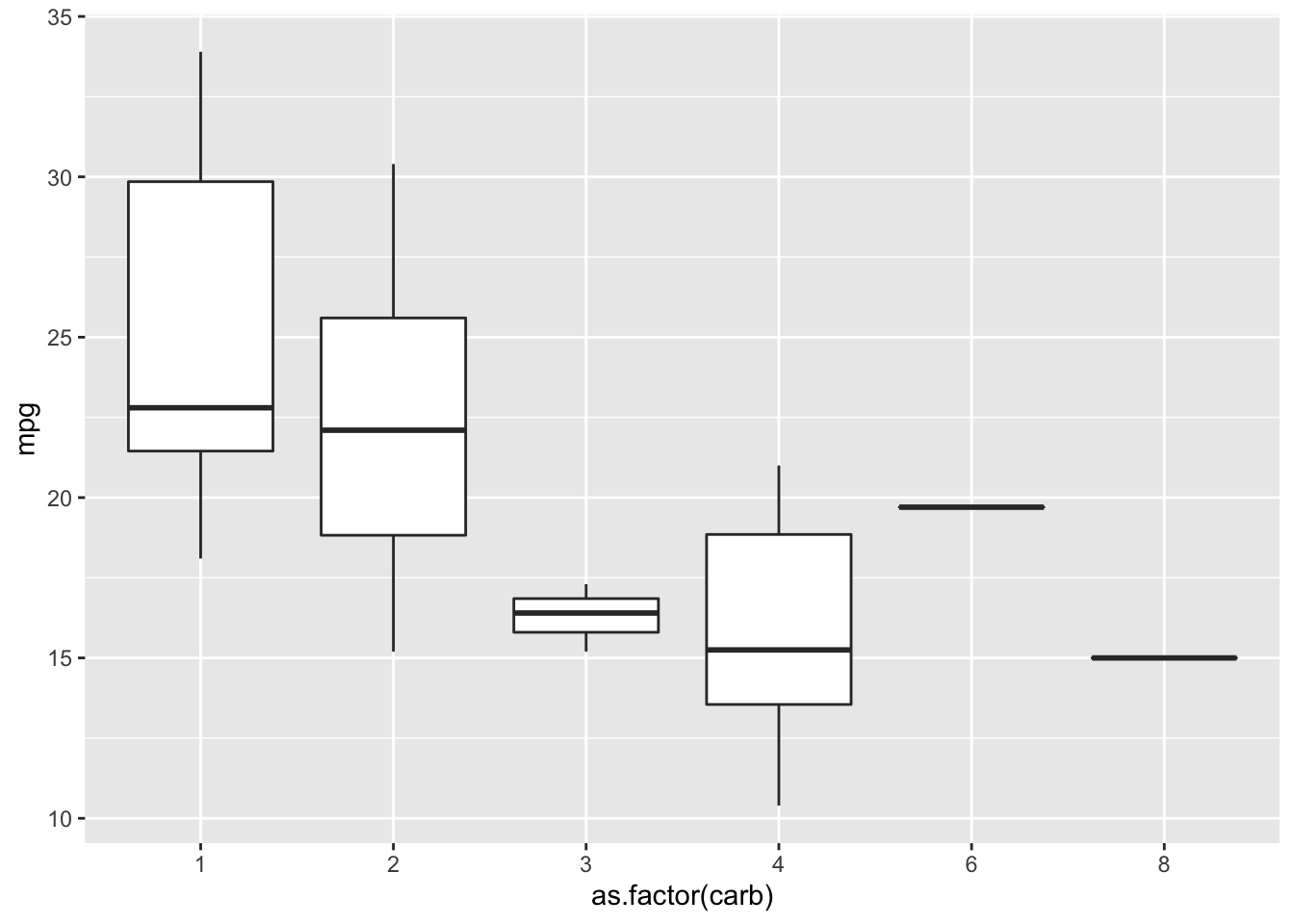
mtcars %>%
mutate(carb = fct_reorder(.f = as.factor(carb),
.x = mpg,
.fun = median)) %>%
ggplot(aes(x = carb, y = mpg)) +
geom_boxplot()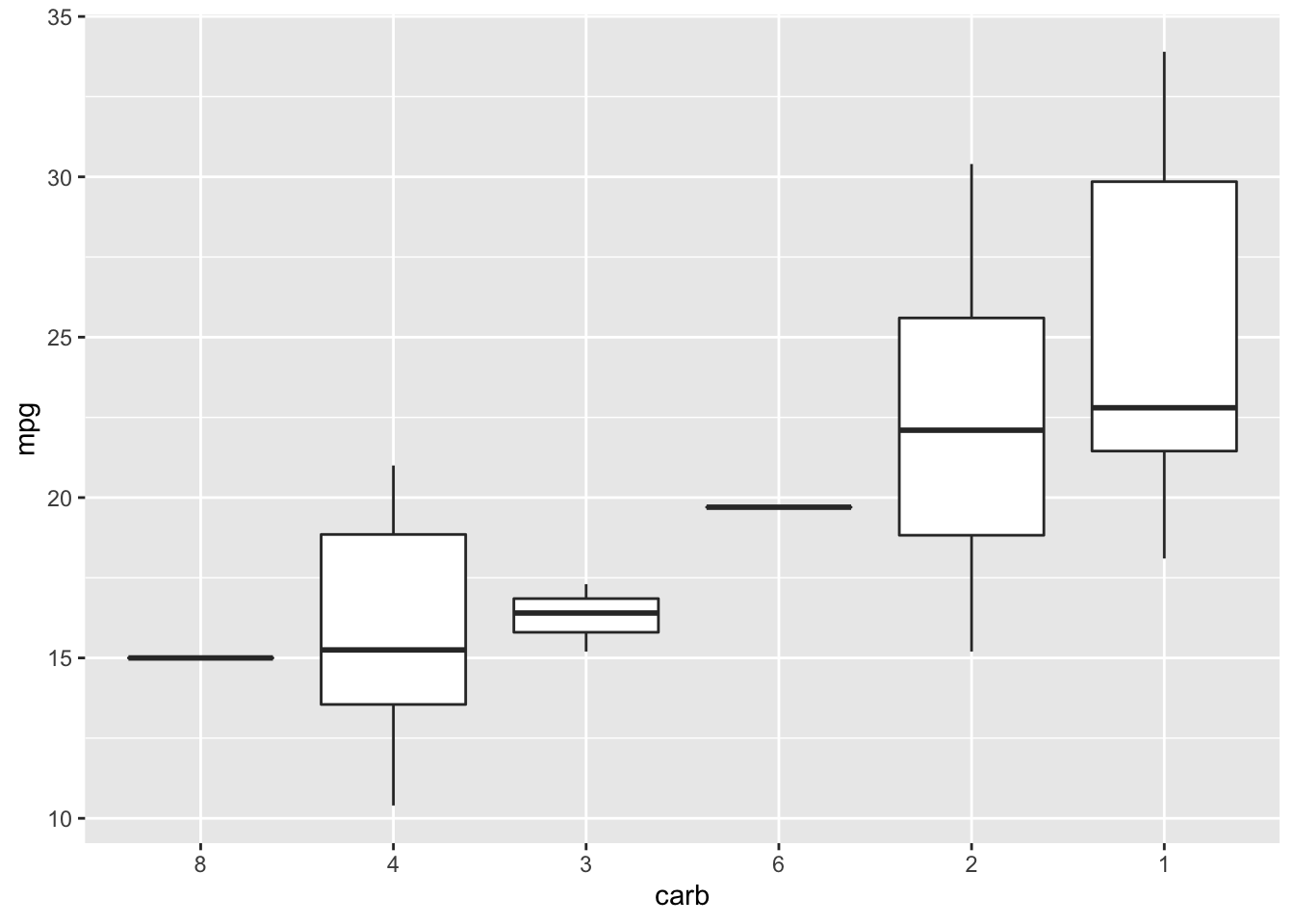
fct_lump
Agrupa as categorias menos (ou mais) comuns.
letras <- factor(letters[rpois(100, 5)])
fct_count(letras)
## # A tibble: 10 × 2
## f n
## <fct> <int>
## 1 b 10
## 2 c 13
## 3 d 12
## 4 e 25
## 5 f 16
## 6 g 6
## 7 h 9
## 8 i 2
## 9 j 4
## 10 l 2
# Por default, a categoria "Other" sempre será menor
# que as outras categorias.
letras %>%
fct_lump(other_level = "Outros") %>%
fct_count
## # A tibble: 10 × 2
## f n
## <fct> <int>
## 1 b 10
## 2 c 13
## 3 d 12
## 4 e 25
## 5 f 16
## 6 g 6
## 7 h 9
## 8 i 2
## 9 j 4
## 10 l 2
# Espeficicando o argumento "n = 4", preservamos os
# 4 valores mais comuns
letras %>%
fct_lump(n = 4, other_level = "Outros") %>%
fct_count
## # A tibble: 5 × 2
## f n
## <fct> <int>
## 1 c 13
## 2 d 12
## 3 e 25
## 4 f 16
## 5 Outros 33
# Espeficicando o argumento "n = -4", preservamos
# apenas os 4 valores que menos aparecem
letras %>%
fct_lump(n = -4, other_level = "Principais") %>%
fct_count
## # A tibble: 5 × 2
## f n
## <fct> <int>
## 1 g 6
## 2 i 2
## 3 j 4
## 4 l 2
## 5 Principais 85lvls_reorder
Troca a ordem das categorias de um fator.
fator <- factor(c("casado", "viuvo", "solteiro", "divorciado"))
fator
## [1] casado viuvo solteiro divorciado
## Levels: casado divorciado solteiro viuvo
lvls_reorder(fator, c(3, 1, 2, 4))
## [1] casado viuvo solteiro divorciado
## Levels: solteiro casado divorciado viuvoO pacote forcats ainda tem outras funções úteis para tratar com fatores, como fct_expand(), fct_explicit_na(), fct_infreq(), fct_reorder2(), lvls_revalue(), entre outras. No RStudio, é sempre útil navegar entre as funções de um pacote digitando, por exemplo, forcats:: e pressionando TAB.
Dúvidas, críticas ou sugestões, deixe um comentário ou nos envie uma mensagem. :)


