Quando eu trabalhei no Núcleo de Estudos da Violência da USP, obter informações da Secretaria de Segurança Pública de São Paulo (SSP) era uma tarefa meio esotérica. Coletávamos os dados de todos os DP’s de São Paulo, que são aproximadamente 100, e, como fazer isso manualmente era demorado, aplicávamos uma solução automática em dois passos. Primeiro raspávamos o site da SSP em Python e depois rodávamos uma macro em VBA chamada “Mestre Dos Magos”, que era responsável por consolidar as séries históricas em excel. Eu achava o procedimento um pouco hermético porque nenhum deles tinha sido feito por mim ou pela minha equipe, era uma herança que a gente não sabia como consertar se desse algum problema. Para dar um exemplo, no final da minha breve estadia no NEV o script não funcionava mais, então era necessário baixar tudo manualmente.
Depois dessa época eu nunca mais mexi com esses dados. Eu sempre tive vontade de implementar uma solução em R, mas sempre faltou motivação. Felizmente, na ultima semana minha namorada precisou dos dados da SSP para um trabalho que está fazendo, só que dessa vez o interesse era em todos os 645 municípios do estado de São Paulo nos anos entre 2013 a 2016. Como não há como baixar todas essas informações de uma vez e downloads individuais tomam muito tempo, eu me senti motivado o suficiente para atacar o problema.
Pra ser sincero, foi bem mais fácil do que eu achei que seria. A construção do programa foi tão simples que cabe até mesmo neste post de blog, mas não é só por isso que ela está aqui. Esse é um exemplo minimal de todas as fases de construção de um scraper.
Os quatro passos para construir um scraper
Em um esquema aproximado, eu acredito que raspar (ou scrappear) um site pode ser feito em 4 passos:
- Defina a página que você quer raspar;
- Identifique exatamente as requisições que produzem o que você quer;
- Construa um programa que imite as requisições que você faria manualmente;
- Repita o passo 3. quantas vezes quiser.
Mesmo que existam scrapers mais complicados, é verdade que seguir esses passos pelo menos te ajuda a chegar mais perto do que você realmente precisará fazer depois.
Defina o que você quer
Tanto o NEV quanto a minha namorada tinham interesse nas tabelas que apareciam numa URL específica do site: http://www.ssp.sp.gov.br/Estatistica/Pesquisa.aspx. A lógica por trás da divulgação dessas informações é a seguinte: você escolhe um ano, uma localidade geográfica/administrativa e um tipo de informação e ele te devolve uma tabela. Os anos disponíveis são os anos de 2001 a 2017, as localidades são os cruzamentos entre Municípios, Regiões e Delegacias (notando que você sempre pode escolher “Todos”) e os tipos de informação são taxas de delito, ocorrências registradas por ano, ocorrências registradas por mês e produtividade policial. Nesta aplicação vamos procurar contagens de ocorrências registradas por mês.
Identifique o que o site faz por trás
Identificar o que o site faz por trás provavelmente é a fase mais complicada da construção de um scraper. A dificuldade é que não existe um algoritmo que faça isso pra você. Normalmente eu sigo alguns passos, mas eles exigem uma dose de insight para funcionar, o que implica que talvez não seja possível seguir todos os passos em sequência.
- Entre na página imediatamente anterior à página que você quer acessar.
- Abra as ferramentas de desenvolvedor dos seu navegador (isso normalmente é equivalente à “aperte F12”).
- Selecione a aba “Network” (ou “Rede”) na caixa de ferramentas do desenvolvedor.
- Vá para a página que você quer.
- Na lista de requisições que o site fez ao servidor, identifique aquela(s) que é(são) relevante(s) a sua pesquisa.
Parece muito louco né? No geral, é muito louco sim, mas quando você dá sorte é fácil. Vou mostrar o que acontece no nosso exemplo:
A página imediatamente anterior
Eu quero a url http://www.ssp.sp.gov.br/Estatistica/Pesquisa.aspx com alguma seleção, então pra realizar o primeiro passo basta entrar em http://www.ssp.sp.gov.br/Estatistica/Pesquisa.aspx.
Ferramentas do desenvolvedor e aba “Network”
Em qualquer navegador, as ferramentas do desenvolvedor mostram o background do que aparece na tela. Se estiver nessa aba, quando você entrar em http://www.ssp.sp.gov.br/Estatistica/Pesquisa.aspx e apertar F5, vai encontrar uma tela mais ou menos parecida com a tela abaixo:
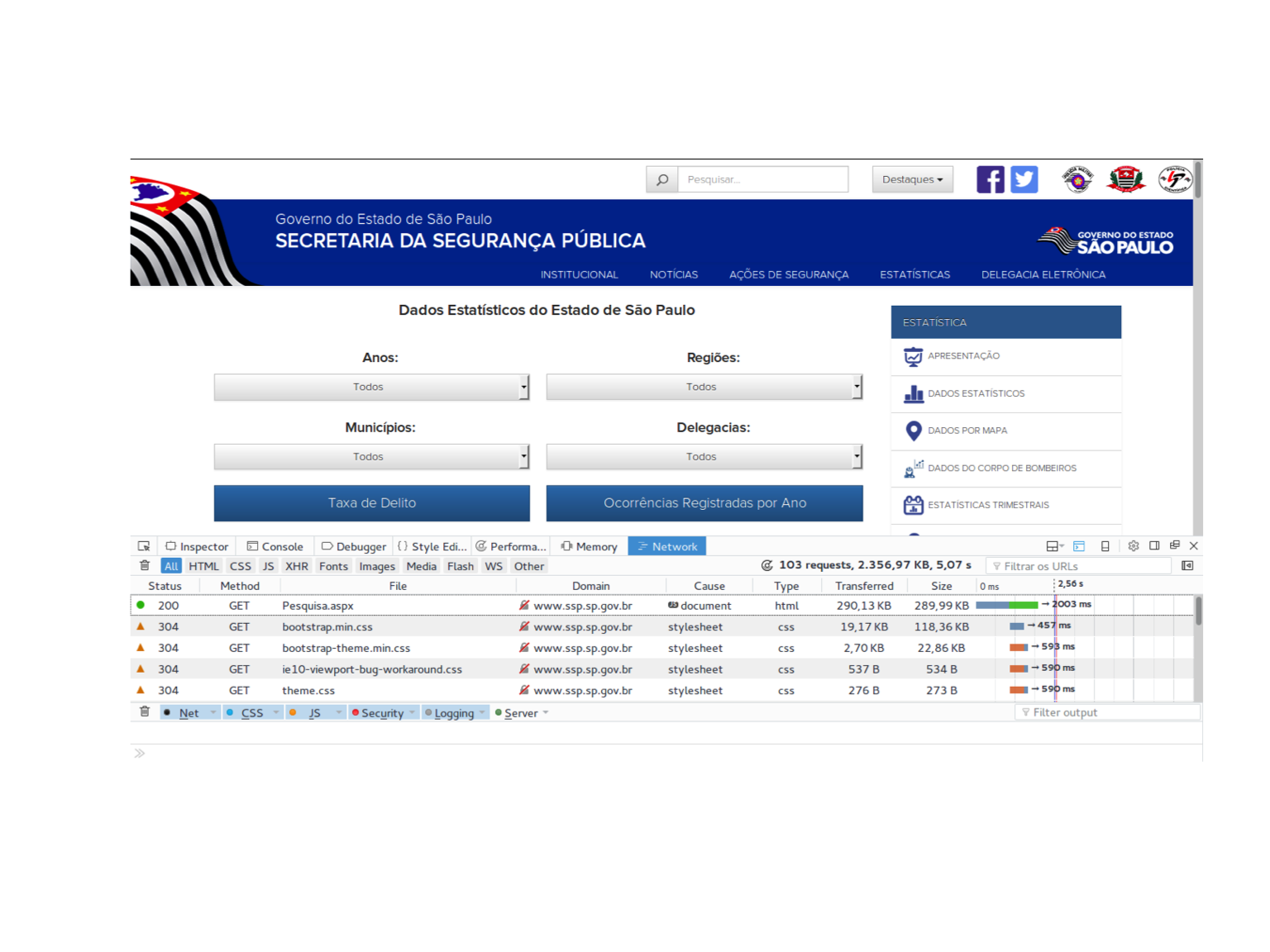
Cada linha representa uma requisição, que é essencialmente o envio de um arquivo .html ao servidor. O conteúdo que visualizamos na tela é o resultado de todas essas requisições e, se destrincharmos cada uma delas, podemos identificar aquelas que são relevantes para o nosso problema.
A requisição
O próximo passo é identificar o que é que o navegador pede ao servidor quando te devolve o que você quer. Se você escolher o ano de 2017 na caixa de seleção de anos, por exemplo, vai encontrar uma tela parecida com essa aqui.
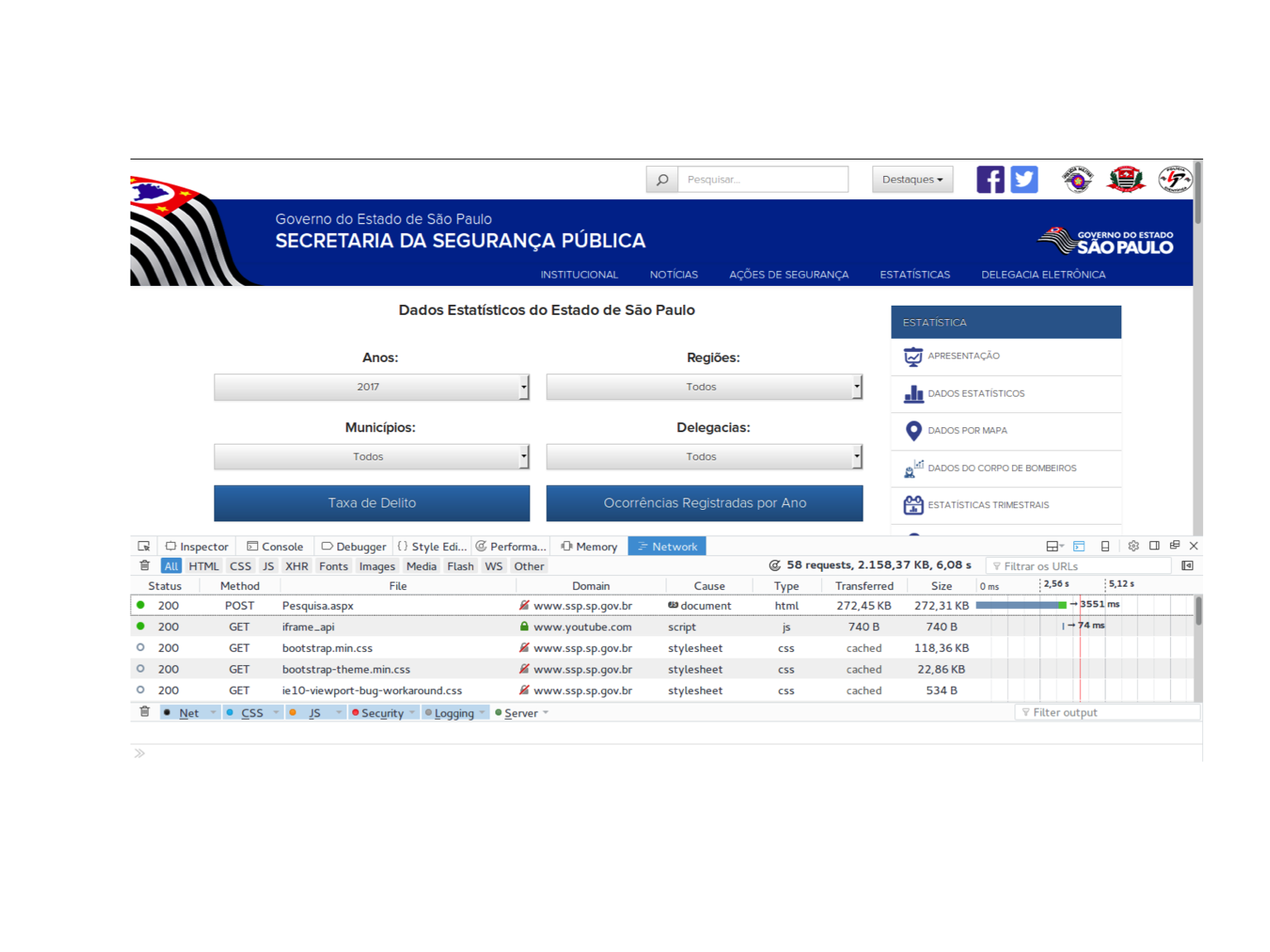
Antes de prosseguir, é necessário fazer uma inspeção meticulosa de todas as requisições que aparecem, mas vou encurtar a discussão afirmando que a primeira delas é a mais importante. Existem muitas maneiras de deduzir que ela é uma boa candidata, como por exemplo olhando que ela é a única requisição relevante que recebe html, mas vou pular essa parte.
Segundo o nosso dedo duro, a requisição utiliza o método “POST” e, quando clicamos nela, temos informações sobre ela no painel ao lado. Como eu falei acima, uma requisição é um arquivo .html que “pede” alguma ao servidor com base no seu conteúdo. No geral, um bom lugar para procurar o que a requisição está pedindo é o seu conjunto de parâmetros, na aba “Params” do painel de detalhamento da requisição.
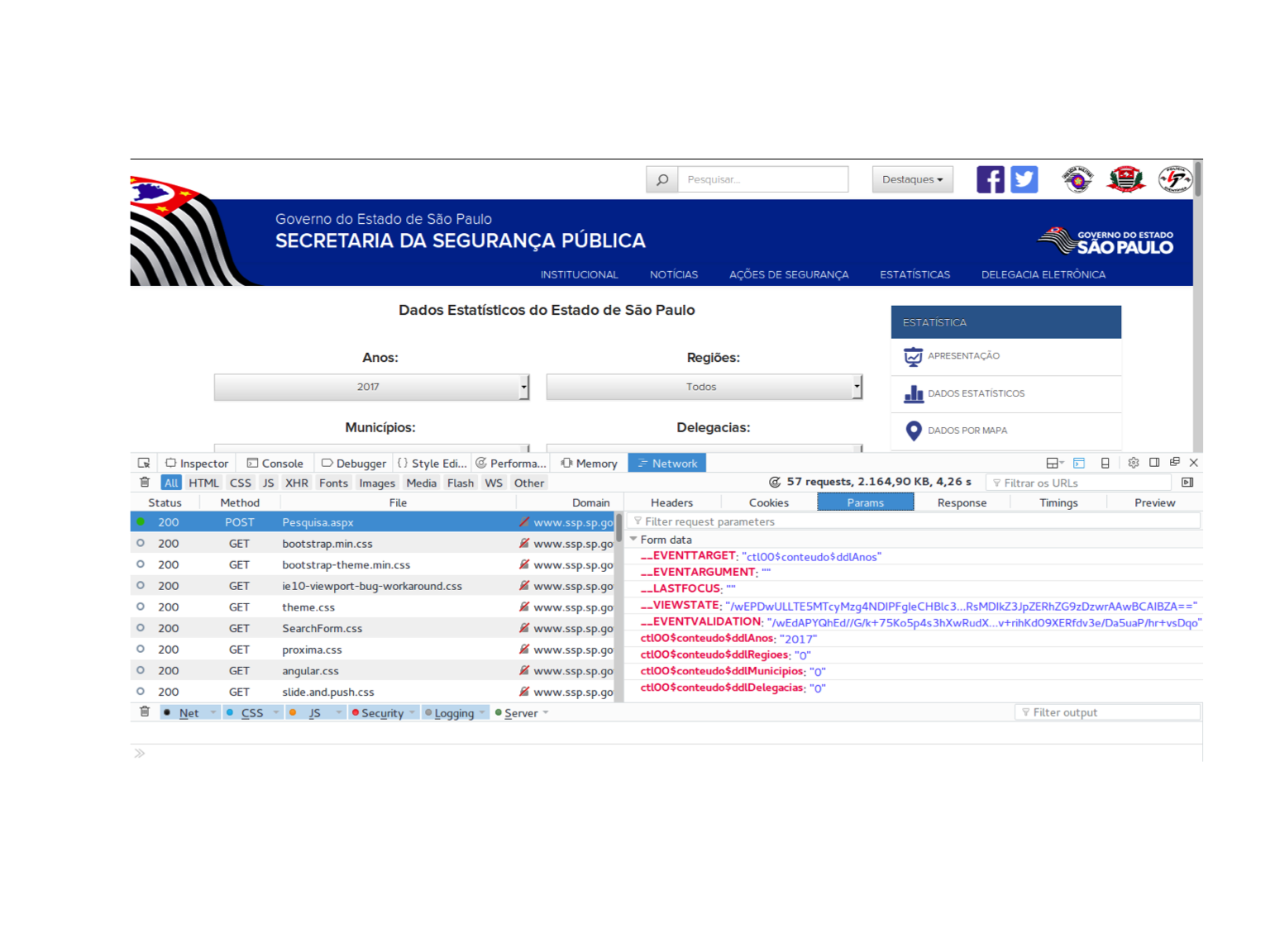
Quando inspecionamos essa requisição “POST”, identificamos que as coisas que são relevantes para o conteúdo da página estão nesses parâmetros. De fato, pensando ingenuamente, clicar apenas em “2017” deve mexer nos parâmetros que tem a ver com isso mas deve deixar os demais parâmetros fixos. Por sorte, os parâmetros observados batem com essa expectativa: “__EVENTTARGET” é ctl00$conteudo$$ddlAnos é um placeholder que tem a ver com a caixa de seleção em que mexemos, os dois próximos parâmetros estão zerados, “__VIEWSTATE” e “__EVENTVALIDATION” são parâmetros da sessão, e, por fim, temos os parâmetros da consulta, que estão todos zerados com exceção de ctl00$conteudo$$ddlAnos.
Parece que os parâmetros tem tudo a ver com a saída. Será que mexer apenas neles basta para copiar a requisição do navegador?
Crie um robô que imita o que um humano faria
Agora que sabemos um pouco mais sobre como as requisições funcionam, vamos tentar fazer o POST mais simples de todos: ele só tem os parâmetros da última imagem. Em R, o jeito mais fácil de fazer requisições é usando o pacote httr. Ele é bem intuitivo e flexível, de tal forma que fazer um POST é feito simplesmente chamando a função httr::POST:
url <- 'http://www.ssp.sp.gov.br/Estatistica/Pesquisa.aspx'
#código para dar um POST vazio no site
httr::POST(url)
#o resultado é simplesmente o resultado original da páginaPara colocar parâmetros num POST, basta usar o parâmetro body. Antes de complicar, vamos tentar o conjunto de parâmetros mais simples de todos: vamos ignorar tudo que a gente não sabe exatamente o que é e preencher só o que sabemos:
params <- list(`__EVENTTARGET` = "ctl00$conteudo$$ddlAnos",
`__EVENTARGUMENT` = "",
`__LASTFOCUS` = "",
`__VIEWSTATE` = "",
`__EVENTVALIDATION` = "",
`ctl00$conteudo$ddlAnos` = "2015",
`ctl00$conteudo$ddlRegioes` = "0",
`ctl00$conteudo$ddlMunicipios` = "0",
`ctl00$conteudo$ddlDelegacias` = "0")Agora vamos fazer a requisição. O passo seguinte é apenas pra traduzir o resultado pra um formato mais fácil de mexer.
resposta <- httr::POST(url,
body = params,
encode = 'form') %>%
xml2::read_html()
# traduz o resultadoComo vamos saber se deu certo? Existem vários jeitos, mas, por simplicidade, aqui vamos apenas checar se alguma tabela contida em resposta é igual à tabela que extraímos manualmente do site. Vamos fazer isso usando a função rvest::html_table().
resposta %>%
rvest::html_table()
# extrai todas as tabelas de um código em html.Como se vê acima, nada que se parece com uma tabela na resposta da nossa requisição é a tabelinha que identificamos no site. Muita coisa pode ter dado errado, mas vamos começar pelo que é mais evidente: nós ignoramos os parâmetros __VIEWSTATE e __EVENTVALIDATION. Em última instância, nos vamos precisar entender o que esses parâmetros significam, mas primeiro vamos tentar simplesmente obter uma cópia desses valores diretamente do site. Dando um ctrl+f no painel de ferramentas de desenvolvedor identificamos que o valores dessa variáveis sai de umas tags input nomeadas de acordo com o parâmetro que representam.
view_state <- httr::POST(url) %>%
xml2::read_html() %>%
rvest::html_nodes("input[name='__VIEWSTATE']") %>%
rvest::html_attr("value")
event_validation <- httr::POST(url) %>%
xml2::read_html() %>%
rvest::html_nodes("input[name='__EVENTVALIDATION']") %>%
rvest::html_attr("value")Com os nossos embustes em mãos, basta pular para a próxima etapa: tentar simular um clique no site. Nosso novo conjunto de parâmetros fica:
params <- list(`__EVENTTARGET` = "ctl00$conteudo$$ddlAnos",
`__EVENTARGUMENT` = "",
`__LASTFOCUS` = "",
`__VIEWSTATE` = view_state,
`__EVENTVALIDATION` = event_validation,
`ctl00$conteudo$ddlAnos` = "2015",
`ctl00$conteudo$ddlRegioes` = "0",
`ctl00$conteudo$ddlMunicipios` = "0",
`ctl00$conteudo$ddlDelegacias` = "0")E o código da requisição fica:
resposta <- httr::POST(url,
body = params,
encode = 'form') %>%
xml2::read_html() %>%
rvest::html_table()Exatamente a tabelinha que queríamos! Entretanto, nem tudo são flores. Como eu mencionei ali em cima, tanto a minha namorada quanto o NEV tinham interesse no número de BO’s, que não é o que obtivemos fazendo a requisição via R. Fuçando um pouco, é fácil ver que o que obtivemos são os números de produtividade policial. Será que é fácil mexer nos parâmetros pra obter os números de BO’s?
Felizmente, a resposta é sim, mas não é tão simples quanto parece. Se de outra tela qualquer você clicar em “Ocorrências Registradas por Mês” você vai perceber que o “__EVENTTARGET” mudou para ctl00$conteudo$$btnMes, mas, a despeito do que se poderia imaginar, os outros parâmetros permaneceram com os nomes intactos.
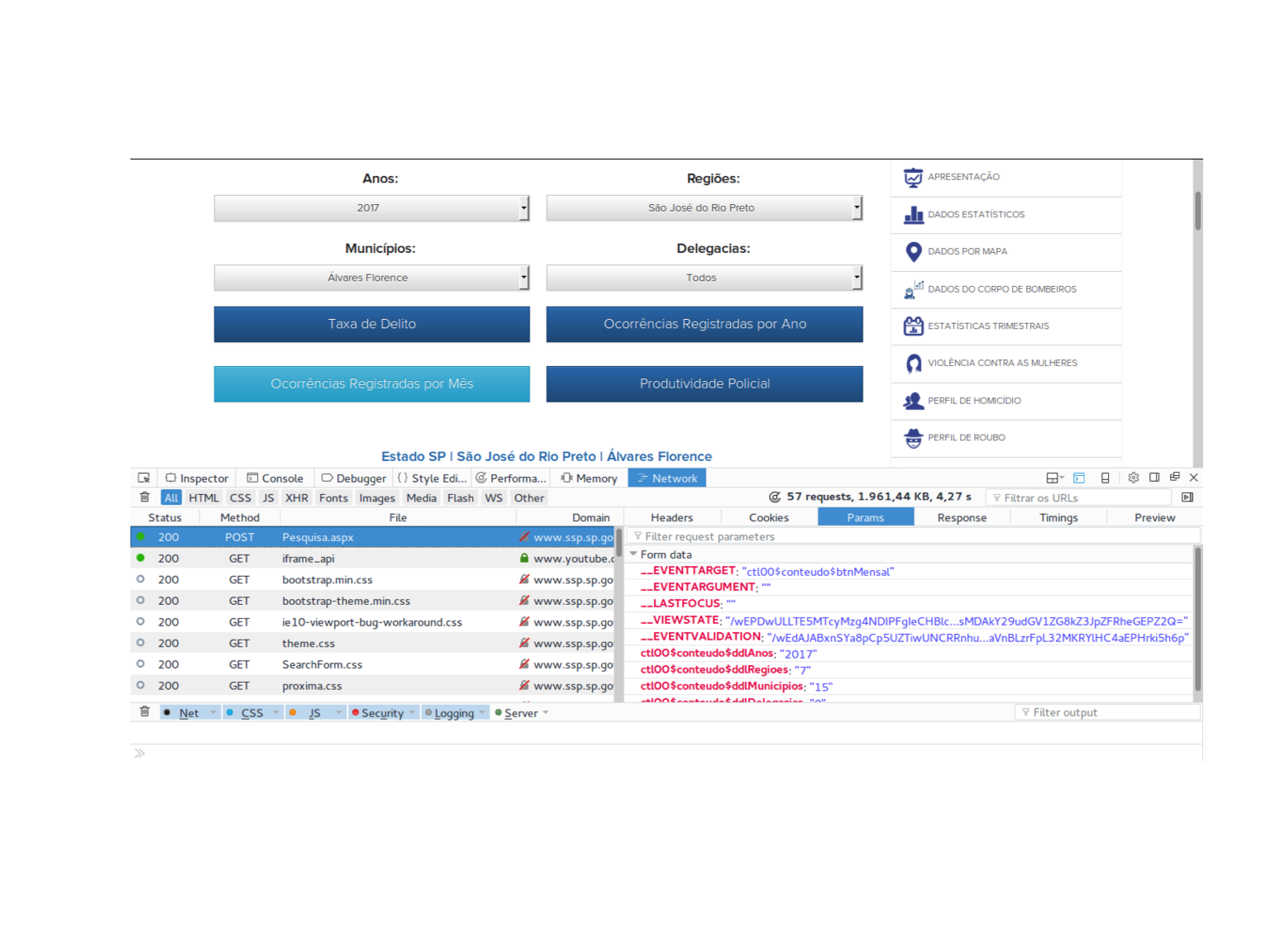
Como essa requisição sugere, você consegue variar os tipos de informação simplesmente variando o “__EVENTTARGET”. Com isso, uma requisição para obter as “Ocorrências Registradas por Mês” ficaria:
params <- list(`__EVENTTARGET` = "ctl00$conteudo$$ddlAnos",
`__EVENTARGUMENT` = "",
`__LASTFOCUS` = "",
`__VIEWSTATE` = view_state,
`__EVENTVALIDATION` = event_validation,
`ctl00$conteudo$ddlAnos` = "2015",
`ctl00$conteudo$ddlRegioes` = "0",
`ctl00$conteudo$ddlMunicipios` = "0",
`ctl00$conteudo$ddlDelegacias` = "0")
resposta <- httr::POST(url,
body = params,
encode = 'form') %>%
xml2::read_html()É importante notar que cada vez que vamos um POST desse, é como se estivessemos entrando na página novamente, de tal forma que as informações que a página tem quando damos vários cliques seguidos são diferentes das informações de quando acessamos a página pelo R. Por exemplo, quando estamos navegando pela página pelos links, o “__EVENTTARGET” volta para ctl00$conteudo$$ddlAnos se você trocar de página saindo de uma página de “Ocorrências Registradas por Mês”, mas o tipo de informação vêm corretamente. Isso acontece porque, se você acessar várias páginas em sequência, a página sabe de onde você veio.
Repita quantas vezes quiser
Agora vem a repetição, o passo final da raspagem. Antes de qualquer coisa precisamos de duas pequenas generalizações: queremos baixar vários anos e vários municípios. Isso é fácil de fazer pois os índices dos municípios são as suas posições em ordem alfabética. Dessa forma, é possível fazer uma função que baixa as “Ocorrências Registradas por Mês” de um município em um determinado ano:
baixa_bo_municipio_ano <- function(ano, municipio){
pivot <- httr::GET(url)
#serve apenas para pegarmos um view_state e um event_validation valido
view_state <- pivot %>%
xml2::read_html() %>%
rvest::html_nodes("input[name='__VIEWSTATE']") %>%
rvest::html_attr("value")
event_validation <- pivot %>%
xml2::read_html() %>%
rvest::html_nodes("input[name='__EVENTVALIDATION']") %>%
rvest::html_attr("value")
params <- list(`__EVENTTARGET` = "ctl00$conteudo$$btnMes",
`__EVENTARGUMENT` = "",
`__LASTFOCUS` = "",
`__VIEWSTATE` = view_state,
`__EVENTVALIDATION` = event_validation,
`ctl00$conteudo$ddlAnos` = "2015",
`ctl00$conteudo$ddlRegioes` = "0",
`ctl00$conteudo$ddlMunicipios` = municipio,
`ctl00$conteudo$ddlDelegacias` = "0")
httr::POST(url, body = params, encode = 'form') %>%
xml2::read_html() %>%
rvest::html_table() %>%
dplyr::first() %>%
#' serve pra pegar apenas a primeira tabela da página,
#' se houver mais do que uma. Estou assumindo que a
#' tabela que eu quero é sempre a primeira.
dplyr::mutate(municipio = municipio,
ano = ano)
}Pra ilustar um grande loop, vamos baixar os BO’s de todos os municípios, no ano de 2016. A função demora um pouco pra rodar, então quem quiser ver como fica o resultado final pode clicar neste link.
GRID <- expand.grid(municipio = 1:645, ano = '2016', stringsAsFactors = F)
D <- purrr::by_row(GRID, baixa_bo_municipio_ano, .to = "ocorrencias") %>%
tidyr::unnest(ocorrencias)Resultados
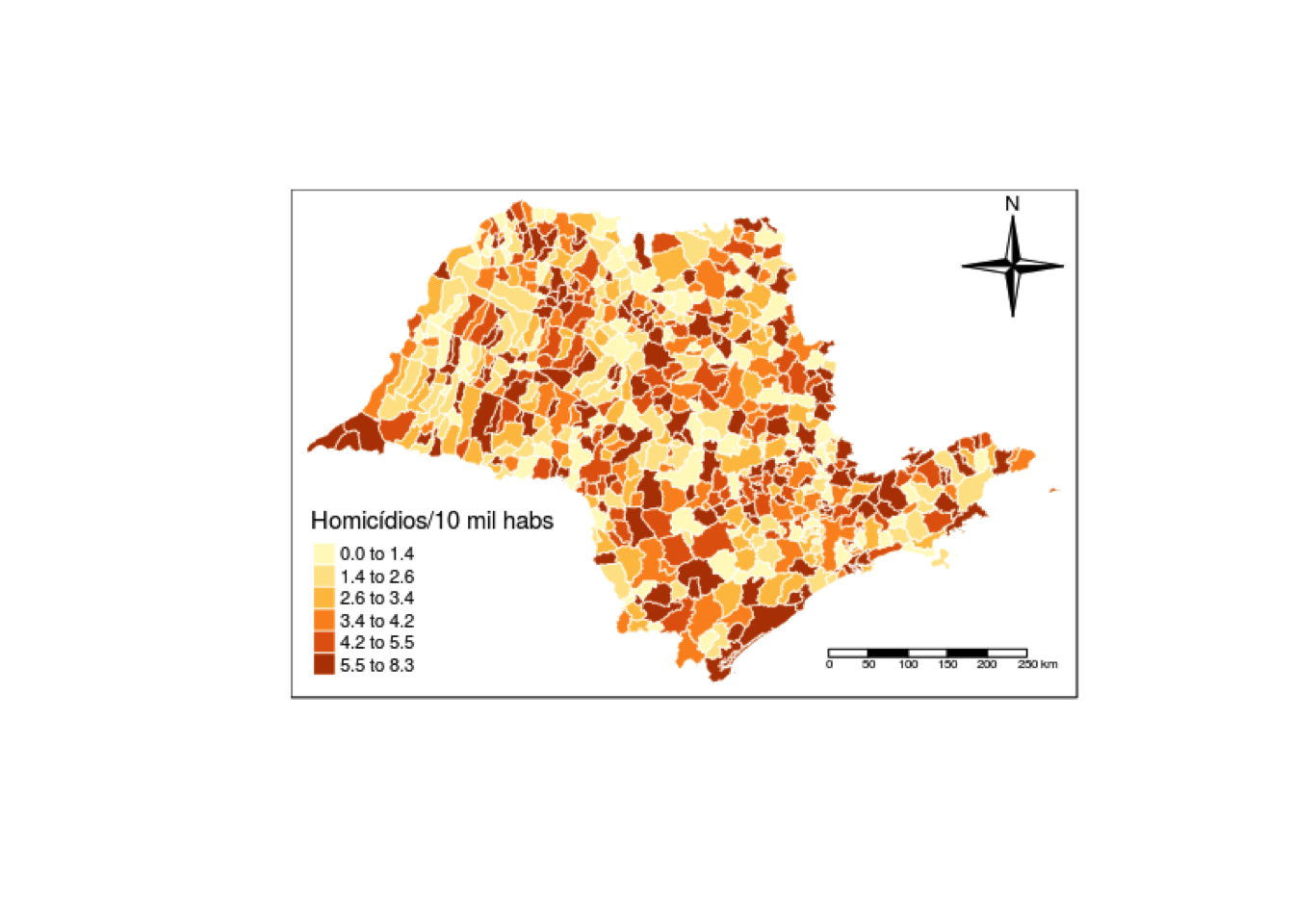
Com esses dados dá pra fazer muitas coisas legais. É possível, por exemplo, fazer mapas como esse, que representa o número de homicídios em 2016, por município. Ele foi feito em R, mas como fazê-lo é assunto pra outro post!