No dia em que fui ao Lollapalooza eu descobri o Rspotify, um wraper da API do Spotify e daí me veio a ideia de juntar infos dos dois assuntos.
A brincadeira aqui vai envolver
- Web Scraping - para baixar e estruturar as tabelas de programação do Lolapalooza SP 2017
- API do Spotify - por meio do pacote Rspotify
- todos os pacotes do tidyverse
Lollapalooza deste ano em São Paulo contou com 47 bandas distribuídas em quatro palcos. A graça é associar a programação do Lolla com as informações de popularidade das bandas fornecidas pelo Spotify. Abaixo eu vou descrever como peguei os dados, listar as três hipóteses que criei e gerar alguns gráficos pra discutí-las.
Base de dados
Pré-requisitos
Pacotes
# instala o Rspotify
if(!require("Rspotify"))
devtools::install_github("tiagomendesdantas/Rspotify")library(Rspotify)
library(magrittr)
library(forcats)
library(stringi)
library(lubridate)
library(httr)
library(rvest)
library(tidyverse)O Rspotify é um pacote novo e que ainda não está no CRAN, mas já está funcional.
Conta no Spotify
Para utilizar a API do Spotify é necessário ter um cadastro no site deles, como se pode imaginar.
App no Spotify
Para você receber um código de acesso para usar a API deles é preciso criar um App dentro da sua conta do Spotify, esse é o pré-requisito mais burocrático de todos. Eu aprendi a fazer isso seguindo os passos do README do próprio pacote Rspotify no Github (veja aqui).
No fim, você terá um app_id, um client_id e um client_secret em mãos.
Extraindo programação do Lollapalooza SP 2017
O objetivo aqui é termos uma versão em data.frame das tabelas contidas no site lollapaloozabr.com/lineup-horarios/. Lá tem a agenda completa dos dois dias do evento.
Vamos ao código! Dica: a melhor maneira de aprender o que cada passo do código faz é ir rodando linha a linha e observando o resultado.
# programacao do site do lollapalooza 2017 ----------------------
lolla2017_programacao <- "https://www.lollapaloozabr.com/lineup-horarios/" %>%
GET() %>%
read_html() %>%
html_table() %>%
set_names(c("sabado", "domingo")) %>%
at_depth(2, ~ .x %>%
stri_replace_all_regex(" {2,}", "") %>%
stri_replace_all_regex("[\\n]{1}", ",") %>%
stri_replace_all_regex("[,]{2,}", "\\\n") %>%
read.csv(text = ., header = FALSE,
col.names = c("artist", "hora"))) %>%
map(~ .x[-1] %>%
data_frame(palco = names(.), programacao_palco = .) %>%
unnest(programacao_palco)) %>%
data_frame(dia = names(.), programacao = .) %>%
unnest(programacao) %>%
separate(hora, c("hora_ini", "hora_fim"), sep = "-") %>%
mutate(artist = artist %>% tolower,
hora_ini = paste(if_else(dia %in% "sabado", "2017-03-25", "2017-03-26"), hora_ini) %>% ymd_hm(),
hora_ini = if_else(hour(hora_ini) < 12, hora_ini + hours(12), hora_ini),
hora_fim = paste(if_else(dia %in% "sabado", "2017-03-25", "2017-03-26"), hora_fim) %>% ymd_hm(),
hora_fim = if_else(hour(hora_fim) < 12, hora_fim + hours(12), hora_fim),
dia = fct_relevel(dia, c("sabado", "domingo")))Resultado
| dia | palco | artist | hora_ini | hora_fim |
|---|---|---|---|---|
| sabado | Palco Skol | cage the elephant | 2017-03-25 16:25:00 | 2017-03-25 17:25:00 |
| sabado | Palco Skol | metallica | 2017-03-25 21:00:00 | 2017-03-25 23:00:00 |
| sabado | Palco Skol | doctor pheabes | 2017-03-25 12:05:00 | 2017-03-25 13:05:00 |
| sabado | Palco Skol | rancid | 2017-03-25 18:35:00 | 2017-03-25 19:35:00 |
| sabado | Palco Skol | suricato | 2017-03-25 14:15:00 | 2017-03-25 15:15:00 |
| sabado | Palco Onix | the 1975 | 2017-03-25 17:30:00 | 2017-03-25 18:30:00 |
| sabado | Palco Onix | the outs | 2017-03-25 13:10:00 | 2017-03-25 14:10:00 |
| sabado | Palco Onix | the xx | 2017-03-25 19:40:00 | 2017-03-25 20:55:00 |
É interessante reparar que para gerar essa simples tabelinha utilizamos os pacotes httr, rvest, purrr, dplyr, tidyr, lubridate, stringi e forcats. Só faltou o ggplot2 para zerar o tidyverse.
OBS: 89 fm não é uma banda, era só um espaço reservado para fins de publicidade da rádio.
Extraindo a popularidade das bandas do Lollapalooza no Spotify
Agora vamos usar o pacote Rspotify para extrair as popularidades das bandas que estão listadas no data.frame lolla2017_programacao. Para tanto, usei uma playlist oficial no Spotify feita pela própria equipe do Lollapalooza. Essa playlist é identificada pelo id 1mHoPn6JpbtWtoBuvSXrVm lá no banco de dados do Spotify.
meu_token <- spotifyOAuth(app_id, client_id, client_secret) # coloque aqui suas infos fornecidas pelo Spotify.lolla2017_playlist <- getPlaylistSongs("lollabr", "1mHoPn6JpbtWtoBuvSXrVm", token = meu_token) %>%
mutate(artistInfo = map(artistId, getArtistinfo),
artist = artist %>% tolower) %>%
rename(track_popularity = popularity,
track_id = id) %>%
unnest(artistInfo) %>%
select(artist, id, name, popularity, followers)Algumas bandas ficaram de fora da playlist e por isso fiz uma pesquisa por nome do artista na própria API do Spotify para recuperar o respectivo id. A função que faz isso é a searchArtist().
# recuperando infos dos artistas esquecidos pela playlist ----------------------
possibly_searchArtist <- possibly(searchArtist, NA_character_)
artistas_fora_da_playlist <- lolla2017_programacao %>%
filter(!artist %in% lolla2017_playlist$artist) %$%
artist %>%
data_frame(artist = .) %>%
mutate(search_artist = map(artist, ~ .x %>% possibly_searchArtist),
artist_info = map2(search_artist, artist, ~ {
if(.x %>% is.na) {data.frame(search_artist = NA)} else {
.x %>%
mutate(name = name %>% tolower) %>%
filter(name %in% .y) %>%
head(1)
}})) %>%
select(-search_artist) %>%
unnest(artist_info) %>%
select(artist, id, name, popularity, followers)Resultado
| artist | id | name | popularity | followers |
|---|---|---|---|---|
| ricci | 1EUMh6DZo2CfpolG75YQBL | ricci | 49 | 6116 |
| jimmy eat world | 3Ayl7mCk0nScecqOzvNp6s | jimmy eat world | 66 | 361785 |
| 89 fm | NA | NA | NA | NA |
| martin garrix | 60d24wfXkVzDSfLS6hyCjZ | martin garrix | 85 | 2244761 |
| illusionize | 3RloA7E4XMItSP4FjMBv3L | illusionize | 46 | 30054 |
Juntando tudo
Agora vamos juntar a programação do Lolla com as infos do Spotify. A chave é artist.
lolla2017 <- left_join(lolla2017_programacao,
lolla2017_playlist %>% bind_rows(artistas_fora_da_playlist),
by = "artist") %>%
select(-id, -name) %>%
dplyr::filter(followers %>% is.na %>% not)Base final
| dia | palco | artist | hora_ini | hora_fim | popularity | followers |
|---|---|---|---|---|---|---|
| sabado | Palco Skol | cage the elephant | 2017-03-25 16:25:00 | 2017-03-25 17:25:00 | 72 | 745453 |
| sabado | Palco Skol | metallica | 2017-03-25 21:00:00 | 2017-03-25 23:00:00 | 80 | 3047126 |
| sabado | Palco Skol | doctor pheabes | 2017-03-25 12:05:00 | 2017-03-25 13:05:00 | 20 | 313 |
| sabado | Palco Skol | rancid | 2017-03-25 18:35:00 | 2017-03-25 19:35:00 | 60 | 220182 |
| sabado | Palco Skol | suricato | 2017-03-25 14:15:00 | 2017-03-25 15:15:00 | 41 | 52326 |
| sabado | Palco Onix | the 1975 | 2017-03-25 17:30:00 | 2017-03-25 18:30:00 | 77 | 1600845 |
| sabado | Palco Onix | the outs | 2017-03-25 13:10:00 | 2017-03-25 14:10:00 | 28 | 3788 |
| sabado | Palco Onix | the xx | 2017-03-25 19:40:00 | 2017-03-25 20:55:00 | 76 | 2383923 |
Resultados
Hipótese I
Hipótese I: a organização usou a estratégia de distribuir a popularidade das bandas uniformemente no dia.
Um dos vários desafios logísticos que o evento tem é a alocação das bandas na grade horária nos quatro diferentes palcos.
Eu fui no evento no sábado e ouvi falar que a banda Cage The Elephant tinha sido uma das primeiras bandas a se apresentar. Sabia da popularidade da banda (segundo o Spotify, está mais popular do que The Strokes) e na hora estranhei a decisão do evento de colocá-los para tocar tão cedo.
lolla2017_grafico <- lolla2017 %>%
mutate(hora = map2(hora_ini, hora_fim, ~ seq(.x, .y, 30*60) %>% floor_date("30 minutes"))) %>%
unnest(hora) %>%
group_by(dia, hora, palco) %>%
summarise(artist = first(artist),
n = n(),
mean_popularity = mean(popularity))## `summarise()` has grouped output by 'dia', 'hora'. You can override using the
## `.groups` argument.lolla2017_grafico %>%
ggplot(aes(x = ymd_hm(format(hora, "2017-03-26 %H%M")), y = mean_popularity, colour = palco)) +
geom_line() +
geom_point() +
geom_point(data = lolla2017_grafico %>% filter(artist %in% "cage the elephant"), colour = "red", size = 2) +
geom_text(data = lolla2017_grafico %>% filter(artist %in% "cage the elephant") %>% head(1), aes(label = artist), colour = "red", hjust = 0, vjust = -1) +
facet_wrap(~dia) +
labs(x = "Hora do dia", y = "Popularidade média") +
theme(text = element_text(size = 16))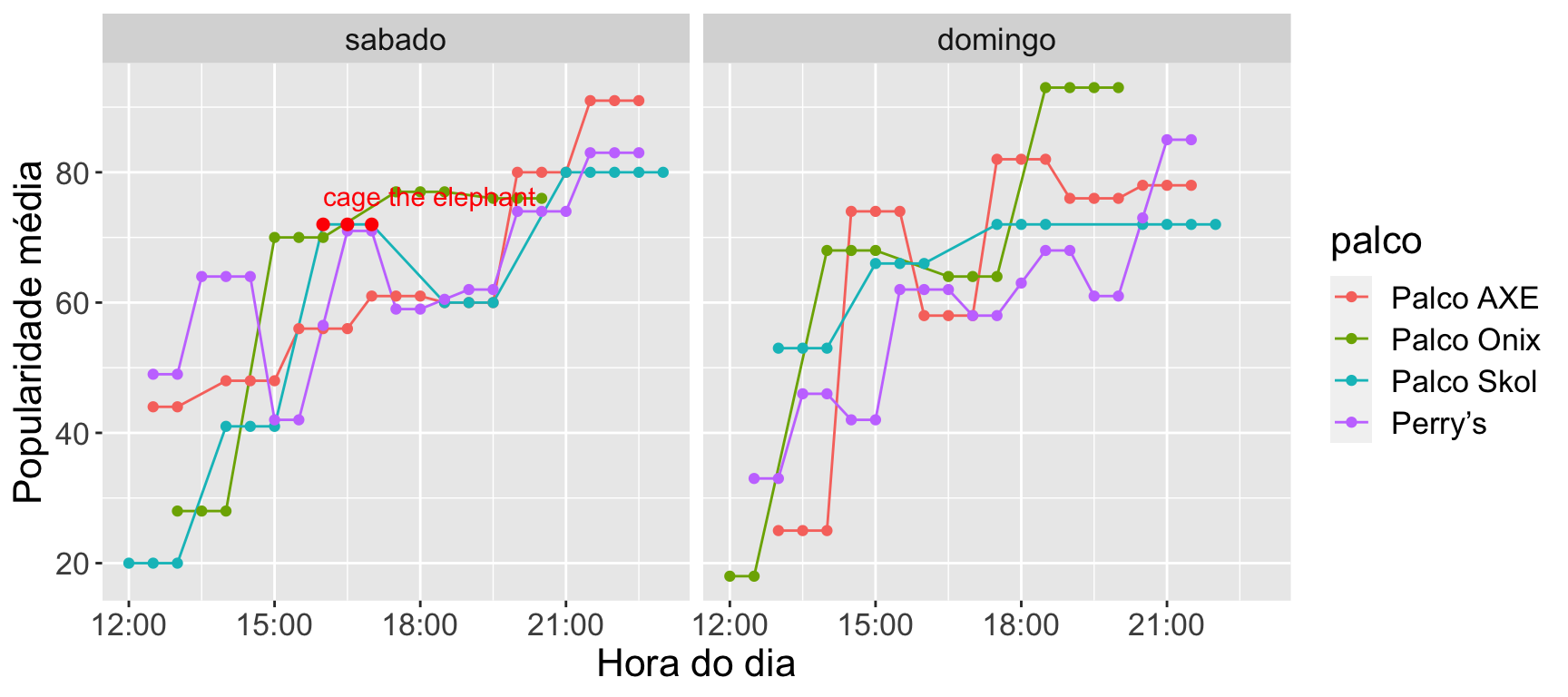
O gráfico acima vai de acordo com o senso comum de que os populares ficam para o final, não ajudando a confirmar a hipótese de que o Cage The Elefant estava mal posicionado.
Hipótese II
Hipótese II: em termos de popularidade das bandas, o dia de domingo estava melhor do que o dia de sábado.
Em conversas com amigos e conhecidos reparei que a maioria ou iria no domingo ou preferiria ir no domingo caso tivesse oportunidade. Isso me fez levantar a dúvida se realmente havia maior concentração de bandas boas no domingo.
ggplot(lolla2017 %>%
mutate(artist = artist %>% fct_reorder(popularity, .desc = TRUE))) +
geom_bar(aes(x = artist, y = popularity, fill = dia), stat = "identity", position = "dodge") +
theme(text = element_text(size = 16),
axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.4))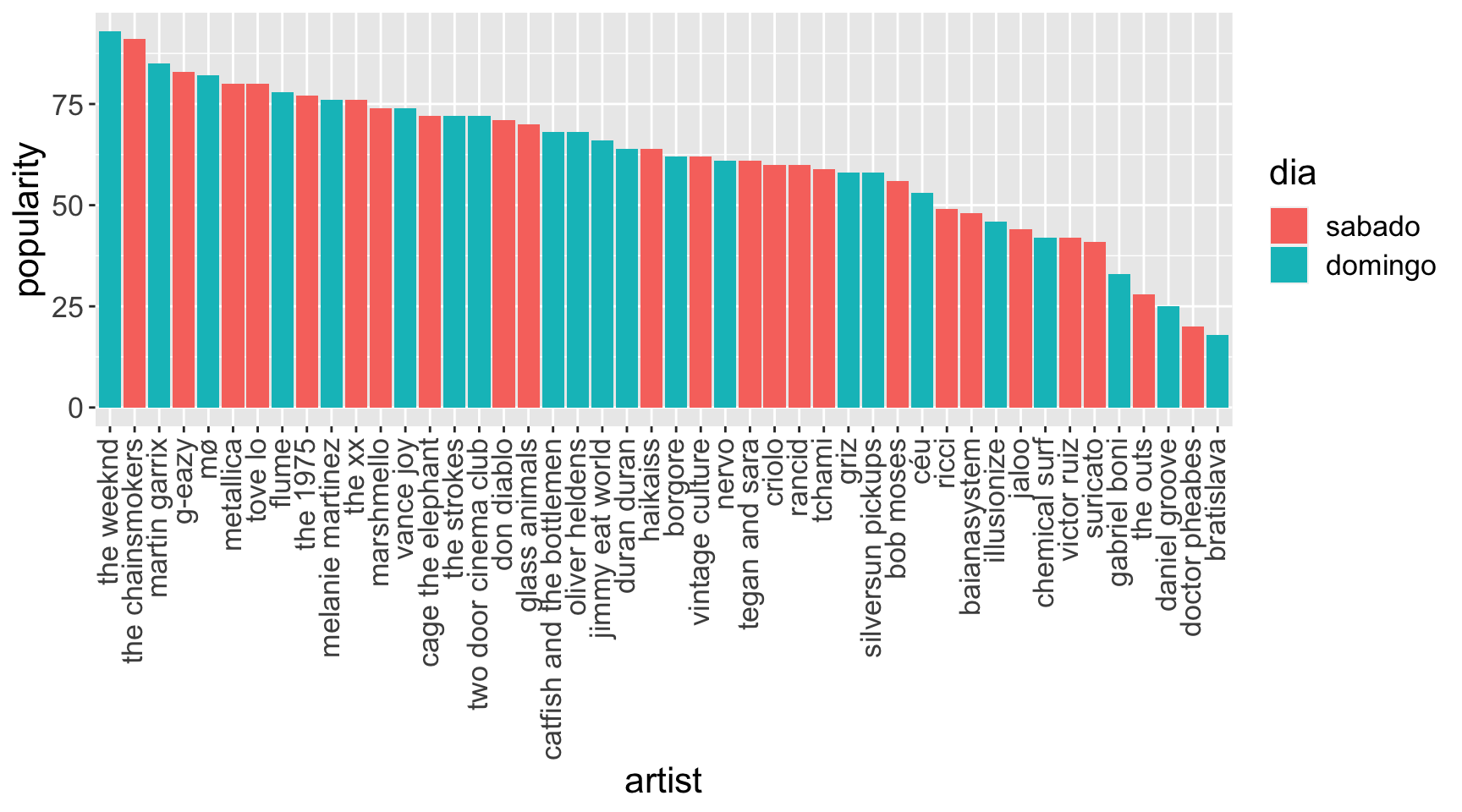
ggplot(lolla2017) +
geom_density(aes(fill = dia, x = popularity, colour = dia), fill = NA) +
theme(text = element_text(size = 16),
axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.4))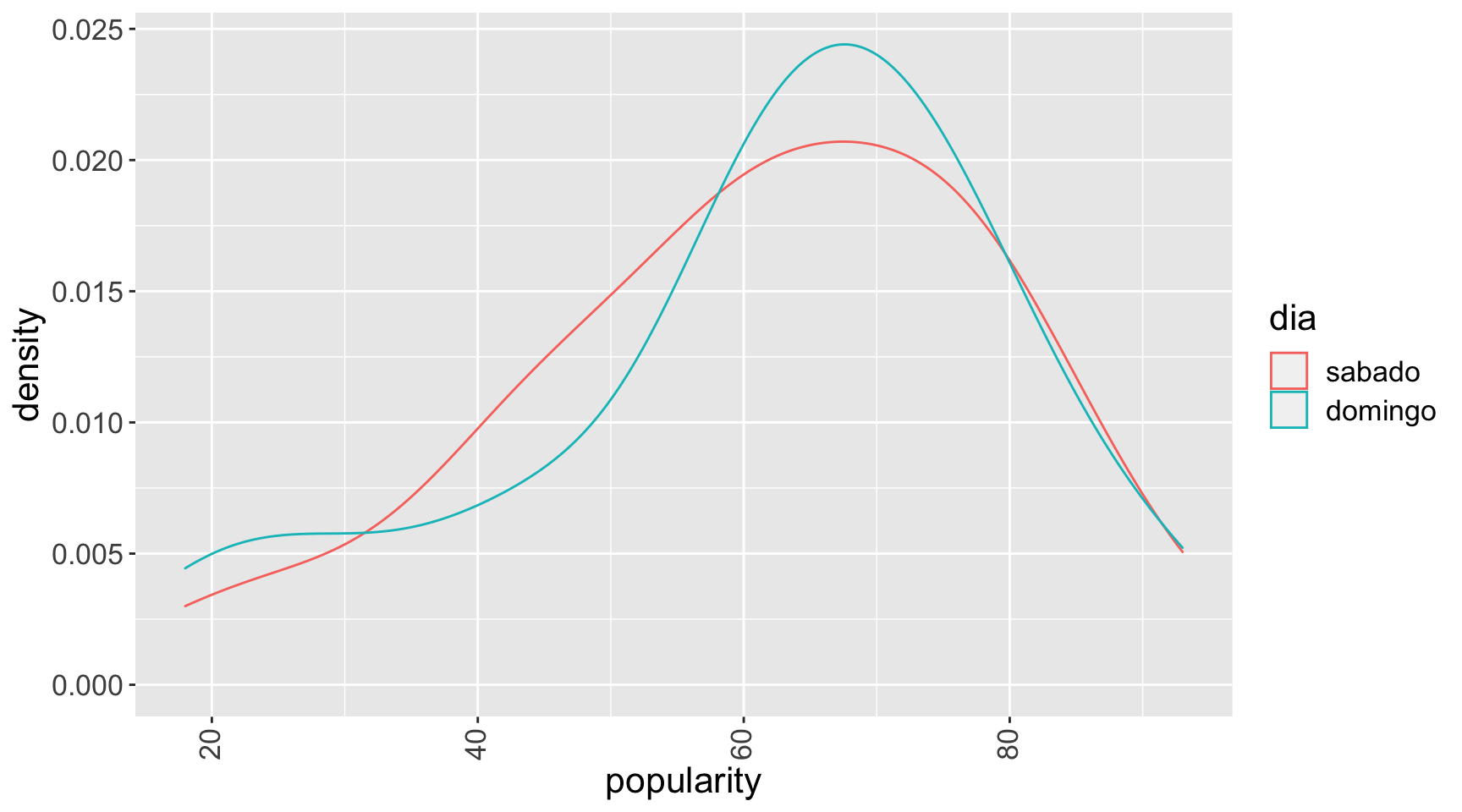
Conclusão: nada indica que houve desbalanceamento. Acho que meu círculo de amigos tem algum viés estranho.
Hipótese III
Hipótese III: a popularidade das bandas nos diferentes palcos estava equilibrada.
Quando me questionei da hipótese I também pensei na dificuldade de posicionar as bandas nos diferentes palcos. Já que teriam milhares de pessoas disputando espaço, seria do interesse da organização deixá-los o mais espalhado possível por vários motivos: melhor fluxo das filas, maior conforto, menos risco de acidentes, entre outros, e um bom jeito de fazer isso seria deixando os palcos igualmente atrativos para não haver uma grande aglomeração em um único ponto.
ggplot(lolla2017 %>%
mutate(palco = palco %>% as.factor %>% fct_reorder(popularity, mean))) +
geom_boxplot(aes(fill = palco, y = popularity, x = 1)) +
theme(text = element_text(size = 16),
axis.text.x = element_blank()) +
labs(x = "")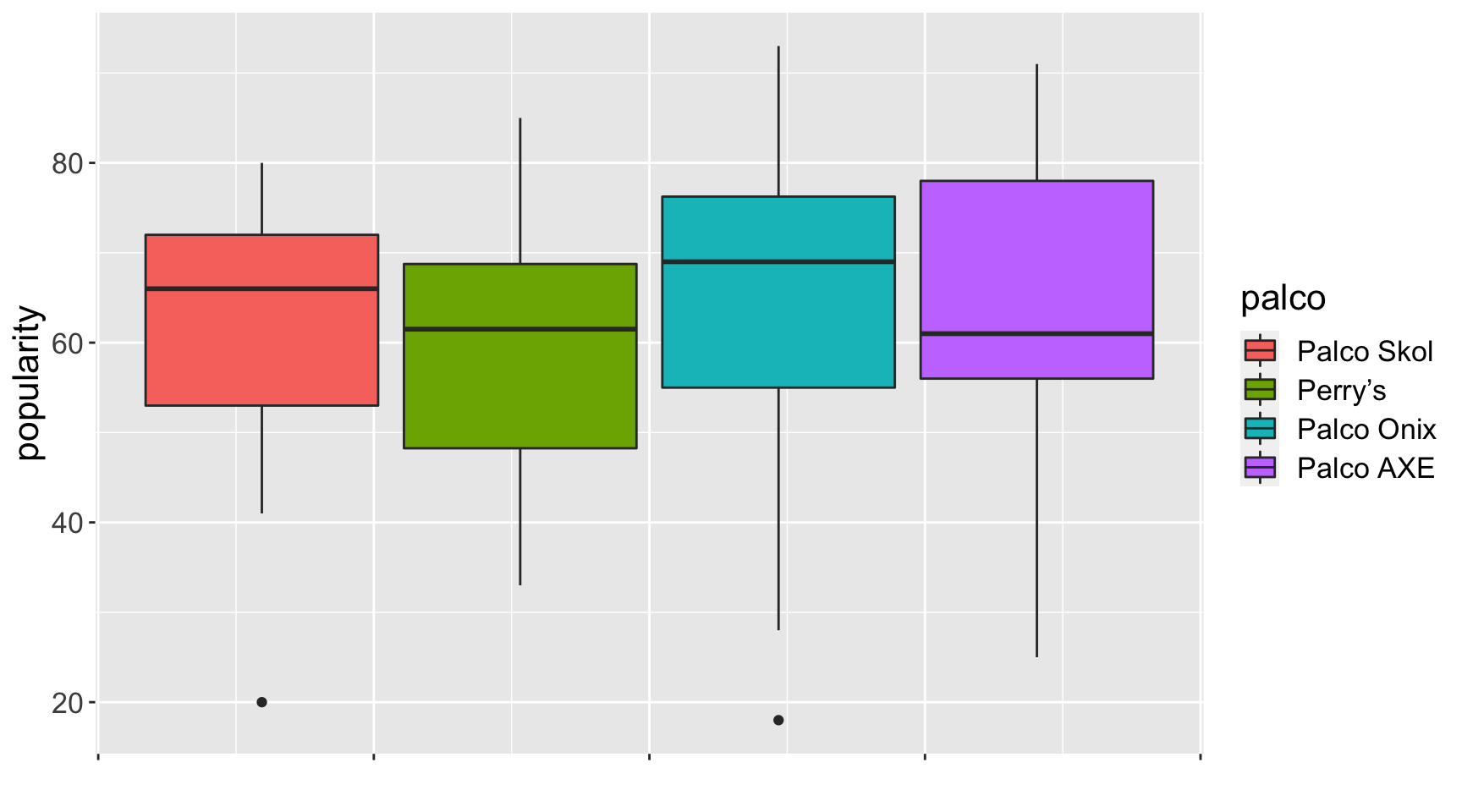
O palco Skol teve menor variação de popularidade, costumou contar sempre com artistas de média a alta popularidade, mas os palcos AXE e Onix foram visitados por artista de peso. O palco Perry’s foi o mais visitado por artistas de menor expressão.
Considerações finais
O tema tratado aqui não foi útil, concordo, mas passamos por quase todas as etapas existentes em um processo típico de análise de dados. Fizemos web scraping, usamos APIs, arrumamos os dados, estruturamos as informações, criamos variáveis e geramos gráficos. Só ficou de fora a parte de modelagem. E não à toa todos os pacotes do tidyverse foram úteis nesse trabalho.
A lição pra casa é encontrar uns dados interessantes na internet e aplicar as etapas que aprendemos aqui!


